复现比赛题目的时候碰到的

[TOC]
参考
[协议层安全相关《http请求走私与CTF利用》_iscc2022让我康康!]-CSDN博客
【WEB】gunicorn走私漏洞_gunicorn漏洞-CSDN博客
发展时间线
最早在2005年,由Chaim Linhart,Amit Klein,Ronen Heled和Steve Orrin共同完成了一篇关于HTTP Request Smuggling这一攻击方式的报告。通过对整个RFC文档的分析以及丰富的实例,证明了这一攻击方式的危害性。
https://www.cgisecurity.com/lib/HTTP-Request-Smuggling.pdf
https://www.cgisecurity.com/lib/HTTP-Request-Smuggling.pdf
在2016年的DEFCON 24 上,@regilero在他的议题——Hiding Wookiees in HTTP中对前面报告中的攻击方式进行了丰富和扩充。
https://media.defcon.org/DEF%20CON%2024/DEF%20CON%2024%20presentations/DEF%20CON%2024%20-%20Regilero-Hiding-Wookiees-In-Http.pdf
https://media.defcon.org/DEF%20CON%2024/DEF%20CON%2024%20presentations/DEF%20CON%2024%20-%20Regilero-Hiding-Wookiees-In-Http.pdf
在2019年的BlackHat USA 2019上,PortSwigger的James Kettle在他的议题——HTTP Desync Attacks: Smashing into the Cell Next Door中针对当前的网络环境,展示了使用分块编码来进行攻击的攻击方式,扩展了攻击面,并且提出了完整的一套检测利用流程。
请求走私漏洞原理
当今的web架构中,单纯的一对一客户端—服务端结构已经逐渐过时。为了更安全的处理客户端发来的请求,服务端会被分为两部分:前端服务器与后端服务器。前端服务器(例如代理服务器)负责安全控制,只有被允许的请求才能转发给后端服务器,而后端服务器无条件的相信前端服务器转发过来的全部请求,并对每一个请求都进行响应。但是在这个过程中要保证前端服务器与后端服务器的请求边界设定一致,如果前后端服务器对请求包处理出现差异,那么就可能导致攻击者通过发送一个精心构造的http请求包,绕过前端服务器的安全策略直接抵达后端服务器访问到原本禁止访问的服务或接口,这就是http请求走私。
听起来是不是有点像SSRF?不过SSRF与HTTP请求走私是有差别的,SSRF是直接利用内网机器来访问内网资源,但请求走私不是。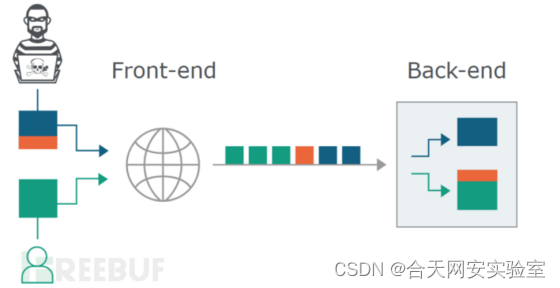
http请求走私攻击比较特殊,它不像常规的web漏洞那样直观。它更多的是在复杂网络环境下,不同的服务器对RFC标准实现的方式不同,程度不同。因此,对同一个HTTP请求,不同的服务器可能会产生不同的处理结果,这样就产生了安全风险。
Keep-Alive&Pipeline
所谓Keep-Alive,就是在HTTP请求中增加一个特殊的请求头Connection: Keep-Alive,告诉服务器,接收完这次HTTP请求后,不要关闭TCP链接,后面对相同目标服务器的HTTP请求,重用这一个TCP链接,这样只需要进行一次TCP握手的过程,可以减少服务器的开销,节约资源,还能加快访问速度。当然,这个特性在HTTP1.1中是默认开启的。
有了Keep-Alive之后,后续就有了Pipeline,在这里呢,客户端可以像流水线一样发送自己的HTTP请求,而不需要等待服务器的响应,服务器那边接收到请求后,需要遵循先入先出机制,将请求和响应严格对应起来,再将响应发送给客户端。
如今,浏览器默认是不启用Pipeline的,但是一般的服务器都提供了对Pipleline的支持。
CL&TE
CL 和 TE 即是 Content-Length 和 Transfer-Encoding 请求头(严格来讲前者是个实体头,为了方便就都用请求头代指)。这里比较有趣的是 Transfer-Encoding(HTTP/2 中不再支持),指定用于传输请求主体的编码方式,可以用的值有 chunked/compress/deflate/gzip/identity ,完整的定义在 Transfer-Encoding#Directives 和 rfc2616#section-3.6
CL好理解,对于TE我们重点关注chunked。当我们设置TE为chunked时,CL就会被省略。为了区分chunk的边界,我们需要在每个chunk前面用16进制数来表示当前chunk的长度,后面加上\r\n,再后面就是chunk的内容,然后再用\r\n来代表chunk的结束。最后用长度为 0 的块表示终止块。终止块后是一个 trailer,由 0 或多个实体头组成,可以用来存放对数据的数字签名等。譬如下面这个例子:
1 | POST / HTTP/1.1 |
另外要注意\r\n占2字节,我们在计算长度的时候很容易把它们忽略。最后把请求包以字节流形式表述出来就是:
1 | POST / HTTP/1.1\r\nHost: 1.com\r\nContent-Type: application/x-www-form-urlencoded\r\nTransfer-Encoding: chunked\r\n\r\nb\r\nq=smuggling\r\n6\r\nhahaha\r\n0\r\n\r\n |
常见走私类型
1.CL不为0
如果前端代理服务器允许GET携带请求体,而后端服务器不允许GET携带请求体,后端服务器就会直接忽略掉GET请求中的Content-Length头,这就有可能导致请求走私。
2.CL CL
在RFC7230的第3.3.3节中的第四条中,规定当服务器收到的请求中包含两个Content-Length,而且两者的值不同时,需要返回400错误。
RFC 7230 - Hypertext Transfer Protocol (HTTP/1.1): Message Syntax and Routing
https://tools.ietf.org/html/rfc7230#section-3.3.3
但是很明显这并非是强制的,如果服务器不遵守安全规定在服务器收到多个CL不相同的请求时不返回400错误,那么就可能会导致请求走私。
我们假设前端服务器按照第一个CL处理而后端服务器按照第二个CL,构造出如下HTTP包:
1 | POST / HTTP/1.1\r\n |
前端代理服务器收到的请求通过第一个CL判断body为8字节,随后将包发送给后端源服务器;源服务器收到请求通过第二个CL判断body为7字节,这时候最后一个字节 b’a’就会被遗留在源服务器缓存器。由于前后端服务器一般是宠用TCP连接,假设此时正常用户向服务器发送了正常的数据包,如下:
1 | GET / HTTP/1.1\r\n |
这时残留在缓存中的一个字节就会被添加到这个正常的请求前端变成:
1 | aGET / HTTP/1.1\r\n |
导致了请求走私,正常数据包被篡改。
但很明显这种情况过于“巧合”应该很难遇见,存在两个CL的包一般服务器都不会接受,在RFC2616的第4.4节中,规定:如果收到同时存在Content-Length和Transfer-Encoding这两个请求头的请求包时,在处理的时候必须忽略Content-Length,这就意味着我们可以在头部同时包含这两种请求头,相比这下这种方式更现实一些。
3.CL TE
所谓CL TE就是前置服务器认为 Content-Length 优先级更高(或者说根本就不支持 Transfer-Encoding ) ,后端服务器认为 Transfer-Encoding 优先级更高。
我们可以构造出body中带有字节 0的请求包,前端服务器通过CL判断这是一个正常的数据包并转发给后端,后端服务器使用TE就会把字节0后的数据滞留到缓冲区,并且与下一次的正常请求进行拼接
4.TE CL
TE CL与CL TE正好相反,假如前端服务器处理TE请求头,而后端服务器处理CL请求头,我们同样可以构造恶意数据包完成走私攻击;依旧使用portswigger的lab:
5.TE TE
TE-TE:前置和后端服务器都支持 Transfer-Encoding,但通过混淆能让它们在处理时产生分歧。
绕过Nginx
文中环境下载地址
1 | https://github.com/cckuailong/nginx_vultarget |
/ 引发的目录遍历
\1. 环境搭建
1 | cd weblogic1/docker-compose up --build -d |
\2. 环境中的nginx配置
1 | location /console/ { deny all; return 403;} |
可以看到,禁止访问 /console,访问 /test 会转发到后端的weblogic服务器
P.S. 此环境weblogic未部署web服务,所以后端的 /hello 会返回404,是正常现象
\3. 绕过解析
服务器配置的规则为 location /test,即/test是作为后面添加字符的前缀。因此,***/test,/test/,/test_anything(包括特殊符号)都可以通过该规则。并且,/test*** 后面的字符将被提取并与 proxy_pass 联合(解析)起来。
Nginx处理完 /test_anything 后,其转发(到后端服务器)的请求格式为
1 | http://server/hello/_anything |
构造
1 | GET /test../other_path HTTP/1.1 |
可以遍历后端服务器的所有位置
首先 /test 与Nginx规则相匹配,然后Nginx提取出 ../other_path,与proxy_pass的***/hello/***相结合,最终转发的请求为:
1 | http://server/hello/../other_path |
则可访问到其他目录
nginx + gunicorn
nginx<1.21.1
gunicorn<20.04
gunicorn和nginx关系
gunicorn 可以单独提供服务,但生产环境一般不这样做。首先静态资源(js/css/img)会占用不少的请求资源,而对于 gunicorn 来讲它本身更应该关注实际业务的请求与处理而不应该把资源浪费在静态资源请求上;此外,单独运行 gunicorn 是没有办法起多个进程多个端口来负载均衡的。
nginx 的作用就是弥补以上问题,首先作为前端服务器它可以处理一切静态文件请求,此时 gunicorn 作为后端服务器,nginx 将会把动态请求转发给后端服务器,因此我们可以起多个 gunicorn 进程,然后让 nginx 作均衡负载转发请求给多个 gunicorn 进程从而提升服务器处理效率与处理能力。最后,nginx 还可以配置很多安全相关、认证相关等很多处理,可以让你的网站更专注业务的编写,把一些转发规则等其它业务无关的事情交给 nginx 做。
漏洞原理
漏洞点gunicorn/gunicorn/http/message.py at 20.x · benoitc/gunicorn (github.com)
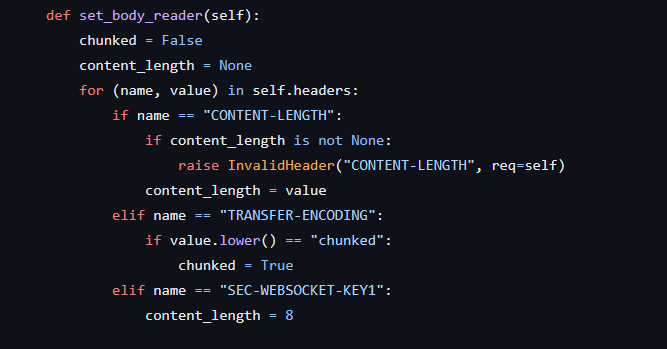
只要header里面存在Sec-Websocket-Key1
那么就将content_length强制赋值为8
POC
1 | GET / HTTP/1.1 |
gunicorn会认为上述请求是两个请求
1 | GET / HTTP/1.1 |
和
1 | GET /other HTTP/1.1 |
但其他的代理服务器则会认为是一个请求,因为没有Sec-Websocket-Key1的逻辑
那么借此就可以绕过gunicorn之外的一些服务器的限制
\1. 环境搭建
1 | cd gunicorn/docker-compose up --build -d |
\2. 环境中的nginx配置
1 | location /public { proxy_pass http://backend:8000;} |
\3. 绕过解析
nginx会将传入的路径进行翻译,如传入
1 | /aaa/bbb/../../ccc |
nginx实际看到的是访问
1 | /ccc |
这个案例的Poc为
1 | /private<TAB>HTTP/1.1/../../public |
根据上面所述,nginx看到的是在访问
1 | /public |
然而gunicorn解析path时会解析成
1 | /private<TAB>HTTP/1.1 |
从而访问到/private目录
; 截断导致前后端解析不一致(Nginx + Weblogic)
\1. 环境搭建
1 | cd weblogic2/docker-compose up --build -d |
\2. 环境中的nginx配置
1 | location /console/ { deny all; return 403;} |
可以看到,禁止访问 /console,访问 / 会转发到后端的weblogic服务器
\3. 绕过解析
nginx会将传入的path进行解析,所以传入的poc是
1 | /console/login/LoginForm.jsp;/../../../ |
nginx解析后会认为传入的是
1 | / |
所以绕过了对 /console的封禁,并转发请求到后端weblogic服务器
weblogic服务器有一个特性是遇到 ; 会进行截断操作,所以实际解析的请求是
1 | /console/login/LoginForm.jsp |
返回了登陆页
weblogic中 # 的妙用(nginx + weblogic)
\1. 环境搭建
1 | cd weblogic1/docker-compose up --build -d |
\2. 环境中的nginx配置
1 | location /console/ { deny all; return 403;} |
可以看到,案例3 配置一样,禁止访问 /console,访问 / 会转发到后端的weblogic服务器
\3. 绕过解析
Weblogic把#作为有效成分,所以可以构造
1 | /#/../console/ |
Nginx处理请求时,它无视了#后面的所有东西,这样可以绕过访问/console/的限制,并转发原始的/#/../console/给Weblogic。Weblogic根据规范处理这个路径,得到的解析结果是
1 | /console/ |
所以进入了/console/目录
CVE-2019-20372-Nginx error_page 请求走私
Nginx 1.17.7之前版本中 error_page 存在安全漏洞。攻击者可利用该漏洞读取未授权的Web页面。
CTF中的应用
NCTF2023 house of click的第一步就是利用nginx + gunicorn绕过然后给本来无权访问的路径下文件传参
也是因为这题了解到了这个知识点,网上搜索学习然后整理了这篇笔记。