
学习Java还是要多看 JDK 源码、框架源码。
前言
Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。
泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
什么是泛型&为什么引入泛型
先来看一段 JDK5 之前没有泛型时的代码
1 | public static void main(String[] args) { |
没有泛型的时候,我们声明的 List 集合默认是可以存储任意类型元素的,乍一看你可能还会觉得挺好,这样功能强大,啥类型都可以存储……但是开发的时候由于不知道集合中元素的确切类型,遍历的时候我们拿到的 item 其实是 Object 类型,如果要使用就必须强转,强转就必须得判断当前元素的具体类型,否则直接使用强转很可能会发生类型转换异常。这样就会让开发很不方便,每次都要额外做判断工作。
那么你可能已经想到了,我们在业务中不要把全部数据都存放在一个 List 就行了,在代码中定义多个 List 分类型使用
1 | public static void main(String[] args) { |
你看上面的代码其实治标不治本,我们声明了 listString 是想让它只存储 String 类型,但是我们仍然可以存储非 String 类型的数据,而且更为重要的是这种类型转换异常通常只有在运行时才会被发现。我们需要一种机制能强制性的让我们只能存储对应类型的元素,否则编译就不通过,所以泛型出现了。
事实上泛型也是我们刚刚的思路,在实例化时给集合分配一个类型,限定一个集合只能存储我们分配的类型的元素
1 | public static void main(String[] args) { |
有了泛型的指定,我们声明的 list 就只能存储规定类型 String ,当存储其他类型的元素时编辑器就会直接给我们报错(可以在 IDEA 开发环境中看 add 方法提示参数类型就是 String),这样类型不匹配的问题就在编译时候就能检查出来,而不会在运行时才抛出异常。而且当我们进行遍历、获取元素等操作时,get 方法返回值就是 String 类型的。
Java泛型可以保证如果程序在编译时没有发岀警告,运行时就不会产生ClassCastException异常。同时,代码更加简洁、健壮。
特性
泛型只在编译阶段有效。看下面的代码:
1 | package Genericity; |
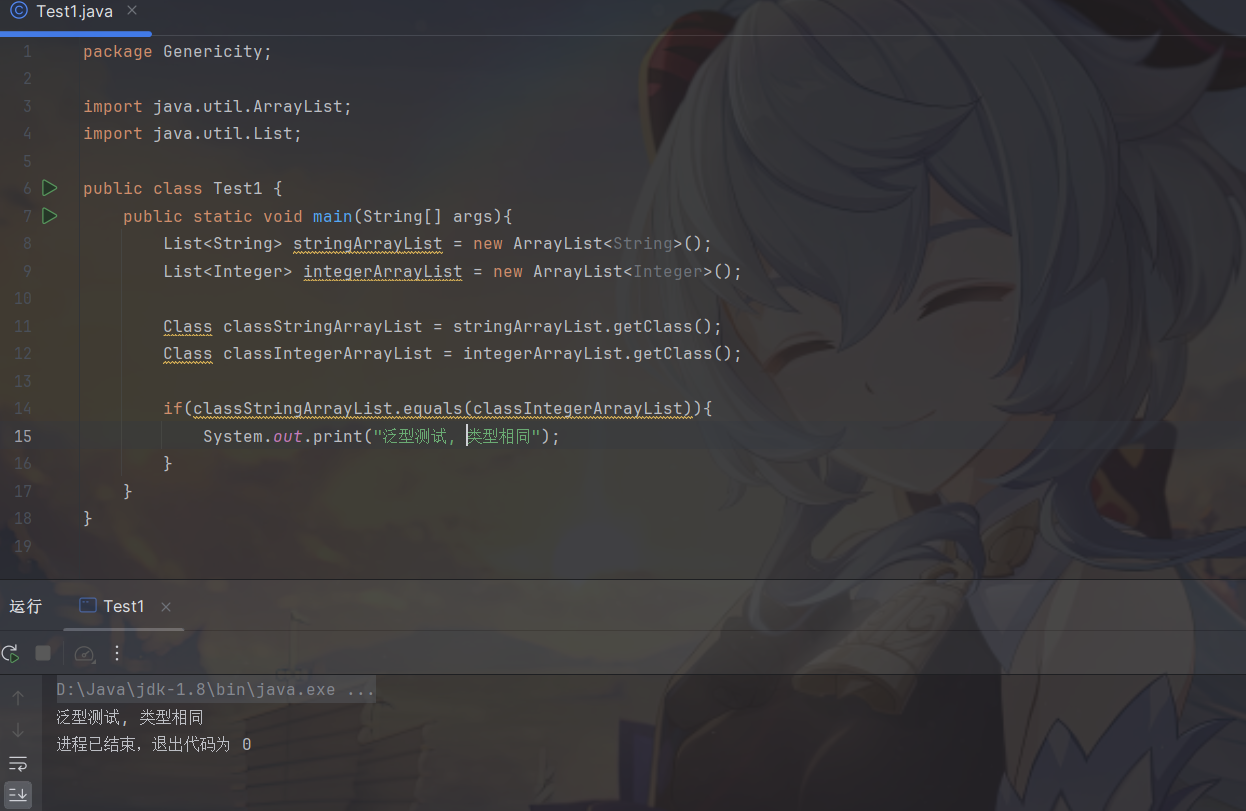
通过上面的例子可以证明,在编译之后程序会采取去泛型化的措施。也就是说Java中的泛型,只在编译阶段有效。在编译过程中,正确检验泛型结果后,会将泛型的相关信息输出,并且在对象进入和离开方法的边界处添加类型检查和类型转换的方法。也就是说,泛型信息不会进入到运行时阶段。
对此总结成一句话:泛型类型在逻辑上可以看成是多个不同的类型,实际上都是相同的基本类型。
泛型方法
一个泛型方法,该方法在调用时可以接收不同类型的参数。根据传递给泛型方法的参数类型,编译器适当地处理每一个方法调用。
下面是定义泛型方法的规则:
- 所有泛型方法声明都有一个类型参数声明部分(由尖括号分隔),该类型参数声明部分在方法返回类型之前(在下面例子中的
)。 - 每一个类型参数声明部分包含一个或多个类型参数,参数间用逗号隔开。一个泛型参数,也被称为一个类型变量,是用于指定一个泛型类型名称的标识符。
- 类型参数能被用来声明返回值类型,并且能作为泛型方法得到的实际参数类型的占位符。
- 泛型方法方法体的声明和其他方法一样。注意类型参数只能代表引用型类型,不能是原始类型(像 int,double,char 的等)。
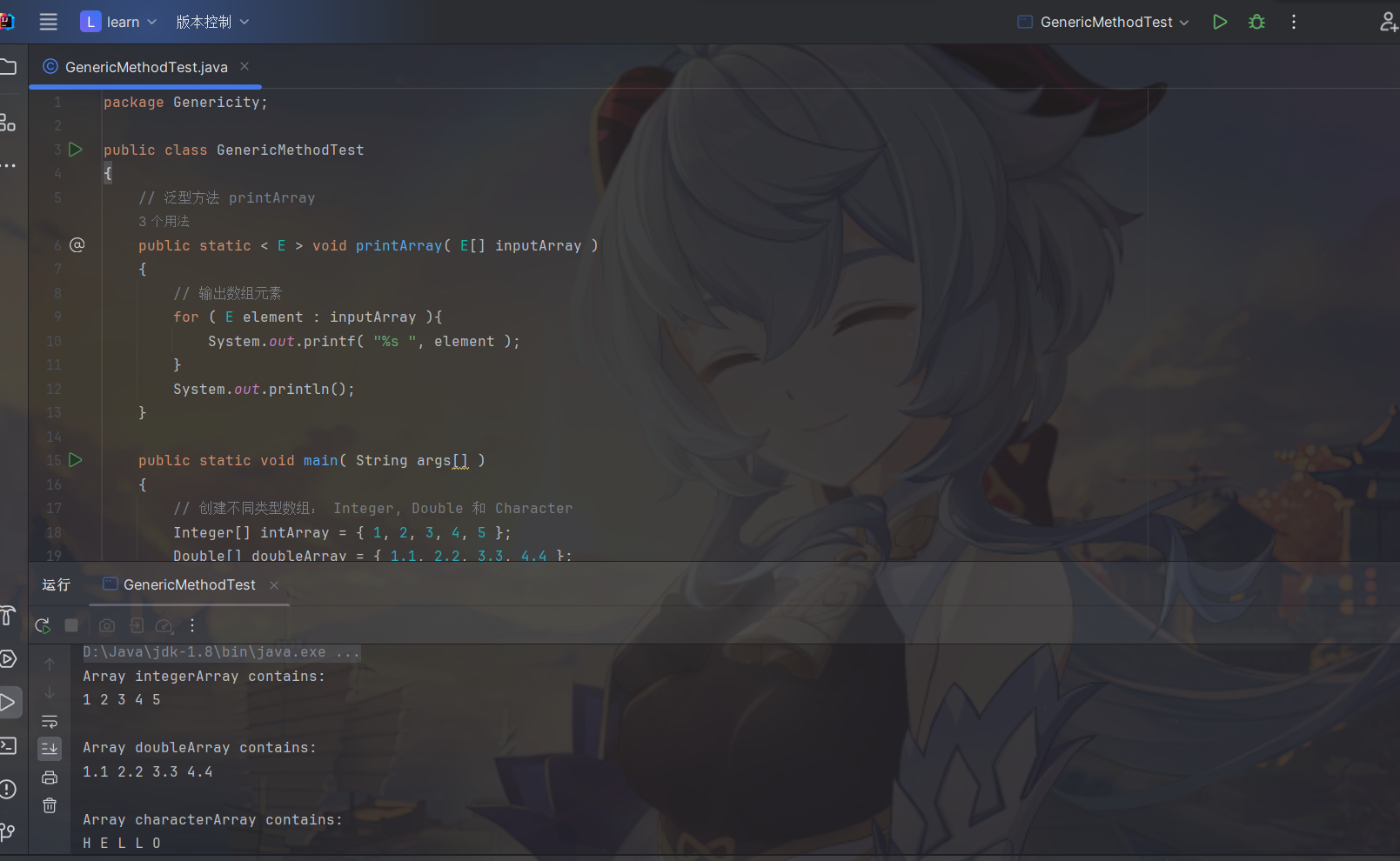
打印不同字符串的元素
1 | public class GenericMethodTest |
泛型类
泛型类的声明和非泛型类的声明类似,除了在类名后面添加了类型参数声明部分。
和泛型方法一样,泛型类的类型参数声明部分也包含一个或多个类型参数,参数间用逗号隔开。一个泛型参数,也被称为一个类型变量,是用于指定一个泛型类型名称的标识符。因为他们接受一个或多个参数,这些类被称为参数化的类或参数化的类型。
说到泛型类,最典型的例子 ArrayList 。你有没有想过,为什么给 ArrayList 指定泛型之后,就只能存储指定类型,get(0) 获取元素返回值就是指定的那个泛型类型?看下 ArrayList 部分源码
1 | //类定义 |
可以看到 ArrayList 在定义的时候指定了一个泛型 <E>,并且下面的添加元素、获取元素等方法也都是对这个 E 进行操作,我相信初学者在看到这个的时候肯定是懵逼的……这个 E 是什么鬼?其实这个 E 就是我们实例化 ArrayList 时指定的类型,当我们指定 String,add 方法的形参和 get 方法的返回值就是 String 类型,当我们指定 Integer,add 方法的形参和 get 方法的返回值就是 Integer 类型。这样一来,ArrayList 这个类就被参数化了,当实例化 ArrayList 时传入不同的泛型就可以操作不同的类型。
当然我们也可以在一个类中定义多个泛型参数,比如 HashMap
1 | public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V> |
回到定义:泛型的本质就是把类型参数化,所操作的数据类型被指定为参数,根据动态传入进行处理
自定义泛型类
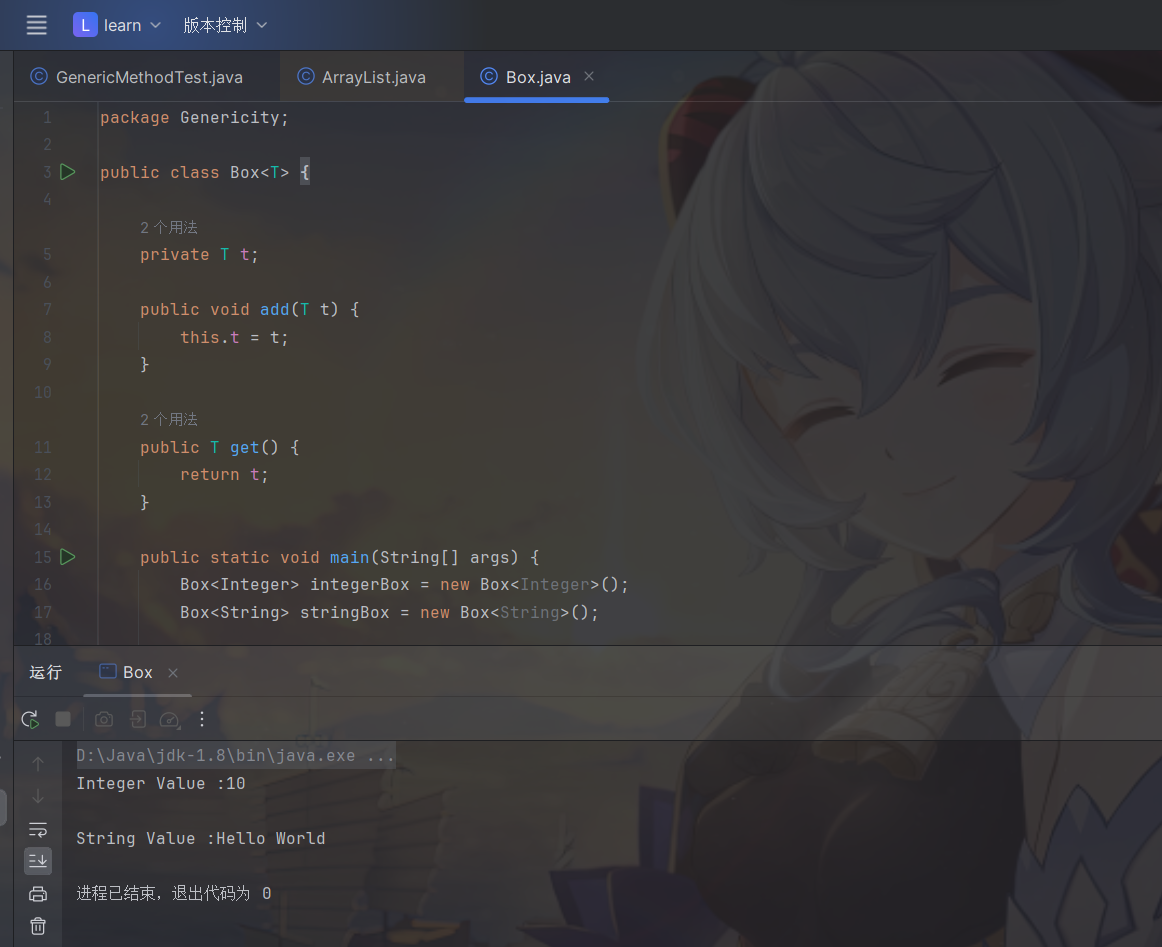
上面我们看到的是 JDK 源码中泛型类,当然我们自己也可以定义泛型类,最常见的就是我们曾经封装的 web 应用后端返回结果。
1 | public class Box<T> { |
泛型接口
先定义一个Dao接口
1 | package Genericity; |
实现类:
1 | package Genericity; |
如果Teacher有类似的操作,那么Dao这个接口就可以直接被复用:
1 | public class TeacherDaoImpl implements Dao<Teacher> { |
泛型通配符
1. 无边界的通配符(Unbounded Wildcards), 就是<?>, 比如List<?>
无边界的通配符的主要作用就是让泛型能够接受未知类型的数据.
2. 固定上边界的通配符(Upper Bounded Wildcards),采用<? extends E>的形式
使用固定上边界的通配符的泛型, 就能够接受指定类及其子类类型的数据。
要声明使用该类通配符, 采用<? extends E>的形式, 这里的E就是该泛型的上边界。
注意: 这里虽然用的是extends关键字, 却不仅限于继承了父类E的子类, 也可以代指显现了接口E的类
3. 固定下边界的通配符(Lower Bounded Wildcards),采用<? super E>的形式
使用固定下边界的通配符的泛型, 就能够接受指定类及其父类类型的数据.。
要声明使用该类通配符, 采用<? super E>的形式, 这里的E就是该泛型的下边界.。
注意: 你可以为一个泛型指定上边界或下边界, 但是不能同时指定上下边界。
泛型通配符 “?” 和 T、E、R、K、V 的区别
我相信这是广大同学最容易混淆的地方,毕竟源码中到处都是这些通配符,也看不出有什么区别。其实 T、E、R、K、V 对于程序运行没有区别,定义泛型的时候用 A-Z 中任何一个字母都可以,只不过我们上面的几个是约定俗成的,也算一种规范。
- T、E、R、K、V 对于程序运行时没有区别,只是名字不同
- ? 表示不确定的泛型类型
- T (type) 表示具体的一个泛型类型
- K V (key value) 分别代表 Map 中的键值 Key Value
- E (element) 代表元素,例如 ArrayList 中的元素
那无界通配符 “?” 和它们有啥区别呢?
- T 用于定义泛型类和泛型方法
比如我们上面 泛型类 的代码示例,用 T 来定义一个泛型,并且可以在代码中对 T 进行操作。而 T 不可以单独作为方法形参,只能在定义的泛型类中或者定义泛型方法才能作为方法形参。
1 | public class ResultHelper<T> implements Serializable { |
- “?” 用于方法形参
比如我们在 无界通配符 “?” 的代码示例,即使不在泛型类中,”?” 也可以作为方法形参,定义方法返回值等,但是我们不能对 “?” 进行单独定义、操作
1 | private List<?> list; |
泛型擦除
所谓的泛型擦除其实很简单,简单来说就是泛型只在编译时起作用,运行时泛型还是被当成 Object 来处理,示例代码
1 | package Genericity; |
输出:
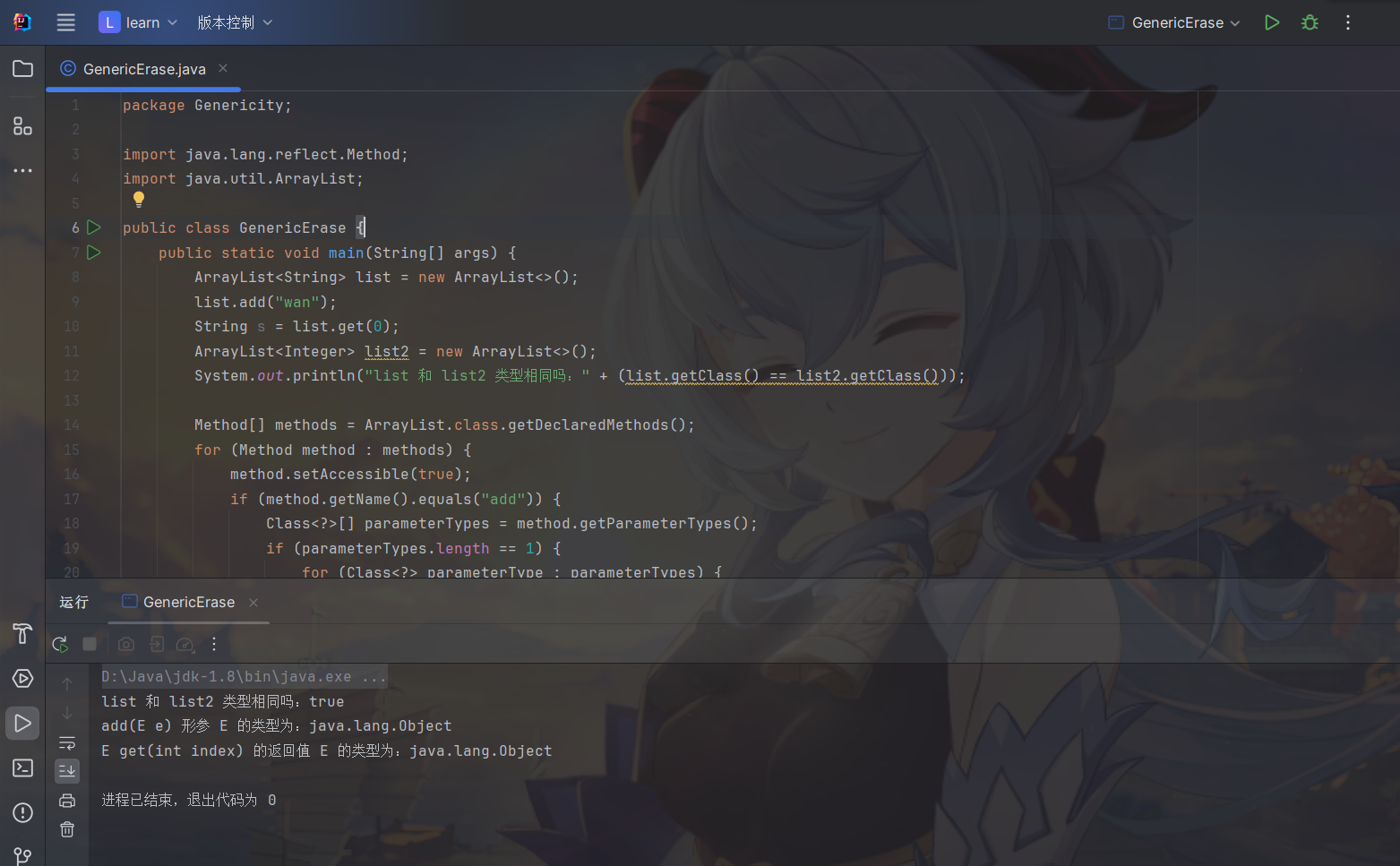
可以看到我们实例化 ArrayList 时虽然传入不同的泛型,但其实它们仍然还是同一个类型。对于 add 方法的形参和 get 方法的返回值,按道理说我们指定的泛型是 String 那么打印出来应该是 String 才对,但是这里运行时得到的却都是 Object,所以这就足以证明了,泛型在编译期起作用,运行时一律被擦除当做 Object 看待,这就是泛型擦除。
这是反编译后的文件
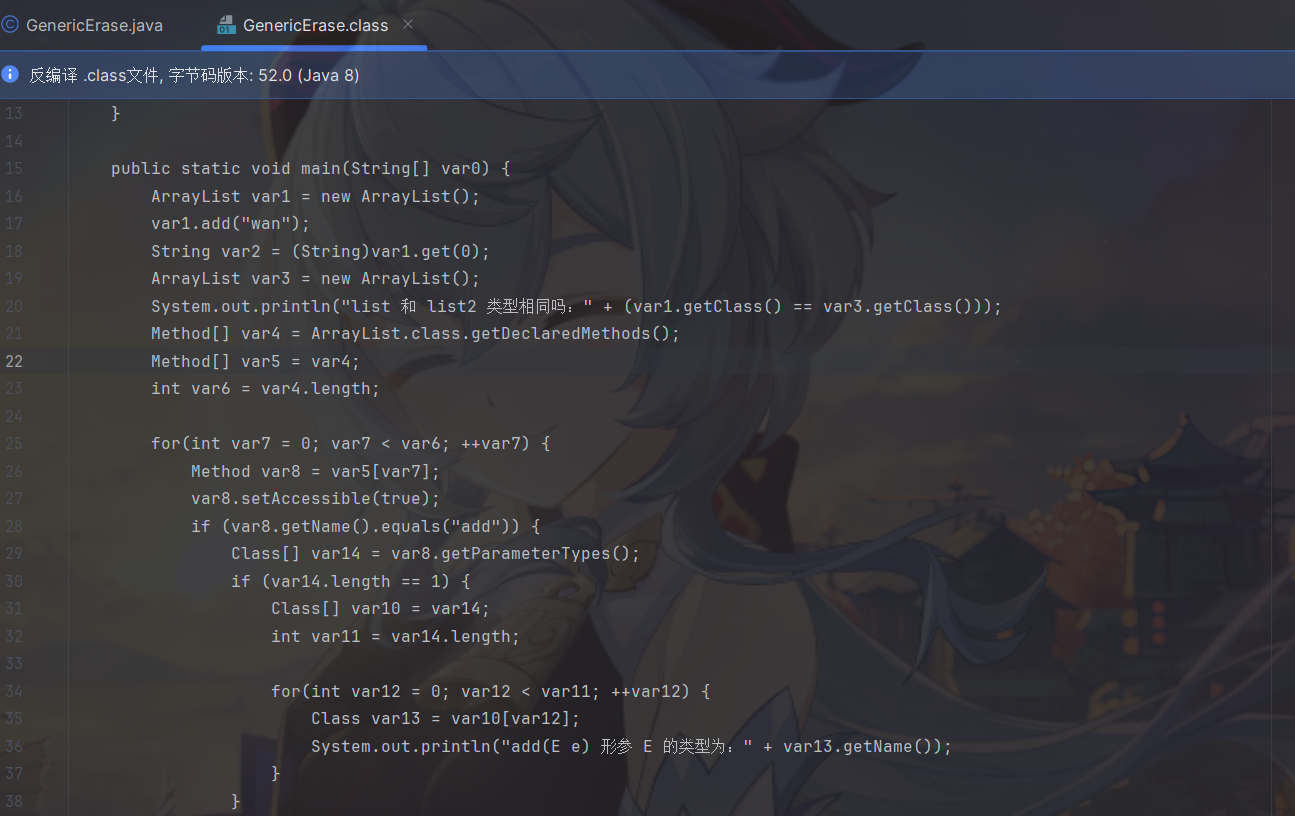
编译器擦除 ArrayList 类后面的两个尖括号,根据输出也可以看出来将add和get方法中的形参E类型定义为 Object 类型
大部分情况下,泛型类型都会以 Object 进行替换,而有一种情况则不是。那就是使用到了extends和super语法的有界类型,如:
1 | public class Caculate<T extends String> { |
这种情况的泛型类型,num 会被替换为 String 而不再是 Object。
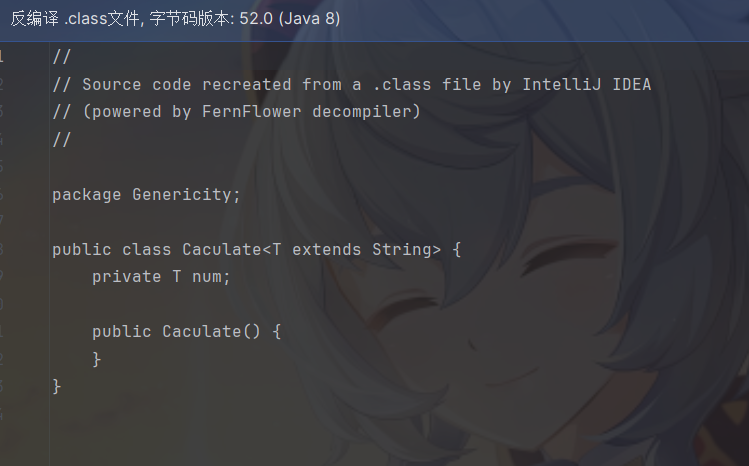
这是一个类型限定的语法,它限定 T 是 String 或者 String 的子类,也就是你构建 Caculate 实例的时候只能限定 T 为 String 或者 String 的子类,所以无论你限定 T 为什么类型,String 都是父类,不会出现类型不匹配的问题,于是可以使用 String 进行类型擦除。
实际上编译器会正常的将使用泛型的地方编译并进行类型擦除,然后返回实例。但是除此之外的是,如果构建泛型实例时使用了泛型语法,那么编译器将标记该实例并关注该实例后续所有方法的调用,每次调用前都进行安全检查,非指定类型的方法都不能调用成功。
实际上编译器不仅关注一个泛型方法的调用,它还会为某些返回值为限定的泛型类型的方法进行强制类型转换,由于类型擦除,返回值为泛型类型的方法都会擦除成 Object 类型,当这些方法被调用后,编译器会额外插入一行 checkcast 指令用于强制类型转换,这一个过程就叫做泛型翻译。
参考:
Java 泛型(泛型类、泛型接口以及泛型方法) - 知乎 (zhihu.com)