又学到了新东西
前言
在数据传输的过程中由于unicode占两个字节,为了减少网络传输的数据量需要转换成UTF接受后再转换为unicode。
这是Java很老的一个漏洞了,但是一直没有被修复。
要先了解一下我们计算机到底是怎样存储字符的,为啥有时候会出现乱码的情况,解决的时候好像要声明什么UTF-8,所以接下来就带着问题一探究竟。
ASCII、UNCIOD、UTF和URI
ASCII
计算机存的都是0、1二进制,咋表示英文字符呢?为了表示英文字符,人们定义了一个标准,这个标准说了,十进制的数字0~127,分别代表一个字符。举个例子,数字65代表英文大写字母A。这套标准,就是所谓的ASCII。注意,这套标准本质上就是定义了一个字符集合,通俗地讲就是用数字来表示字符。
有了这套标准之后,你只要告诉计算机这是ASCII编码,完了告诉它一个数字,它就知道代表什么字符了。
所以接下来问题就是,你要怎么告诉计算机这个数字了。很简单,不就一个128个数字嘛,一个字节有8个二进制位,如果存无符号的,能存256个数(0~255),存放ASCII完全够了。所以只要丢给计算机一个字节,这个字节代表了一个数字,计算机就能得知你要的字符。
UNICODE
ASCII只能表示英文和数字,有没有想过那么多中文怎么办?
因此需要一个更大的字符集合,没错,说的就是unicode了。
unicode又叫统一码、万国码,是一种字符编码标准,旨在涵盖全球范围内的所有字符。它为每个字符分配了唯一的数字编码,可以表示世界上几乎所有的写作系统中的字符,包括不同语言的字母、符号、标点符号和特殊字符。在unicode 15.0.0版本,收录了超过14万个字符。
我们通俗简单的理解就是,unicode的集合比ASCII大,这就够了。
因为大了,所以,告诉计算机这个编号数字的时候,就产生了新问题。
之前ASCII的编号,一个字节就能表示全部的ASCII字符了。现在有14万个字符,一个字节没法表示这么大的编号。那应该用多少个呢?有些字符编号大的,可能得多用几个字节,有的字符编号小的,比如ascii,一百多个编号一个字节就够了,如果统一用固定的字节表示,又很浪费空间,这就是问题所在了。
UTF
于是乎,为了解决这个问题,UTF(Unicode Transformation Format,Unicode转换格式)出现了。
UTF是一种将Unicode字符编码为字节序列的方式,说白了就是为了解决在unicode中,不同大小的编号,要用多少个字节存储的问题。它定义了不同的编码方案,如UTF-8、UTF-16和UTF-32,用于在计算机系统中存储和传输Unicode字符。
UTF-8:UTF-8是一种可变长度的编码方式,使用1到4个字节表示字符。它能够兼容ASCII编码,对于ASCII字符,使用1个字节表示,而非ASCII字符使用多个字节表示。
UTF-16:UTF-16使用16位(2个字节)或32位(4个字节)表示字符。对于Unicode字符,使用2个或4个字节表示。
UTF-32:UTF-32使用32位(4个字节)表示每个字符,无论是ASCII字符还是非ASCII字符。
至此,我们三个基本概念就复习完了。ASCII是一种字符集,Unicode是一种更大的字符集,而UTF是解决Unicode怎么存放和传输的问题。
UTF-8
UTF-8是现在最流行的编码方式,它可以将unicode码表里的所有字符,用某种计算方式转换成长度是1到4位字节的字符。
- Unicode码点是为每个字符分配的唯一数字标识符,说白了就是数字编号。
- 如果码点的范围是U+0000到U+007F(ASCII字符范围),则用一个字节表示,最高位为0。
- 如果码点的范围是U+0080到U+07FF,则用两个字节表示,最高位以110开头。
- 如果码点的范围是U+0800到U+FFFF,则用三个字节表示,最高位以1110开头。
- 如果码点的范围是U+10000到U+10FFFF,则用四个字节表示,最高位以11110开头。
参考这个表格,我们就可以很轻松地将unicode码转换成UTF-8编码:
| First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|---|
| U+0000 | U+007F | 0xxxxxxx | |||
| U+0080 | U+07FF | 110xxxxx | 10xxxxxx | ||
| U+0800 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| U+10000 | U+10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
对于字母A
unicode的码点是0x41。该码点的范围在U+0000到U+007F之间,在计算机中,用1个字节存放,二进制表示就是0100 0001,0100代表4,0001代表1。
对于中文你
unicode的码点是0x4f60,码点的范围在U+0800到U+FFFF之间,即在计算机中需要3个字节存储,那么这时候的算法如下:
将Unicode码点0x4F60转换为二进制数:01001111 01100000(共16位)。
根据UTF-8编码规则,根据码点的范围确定所需的字节数:由于0x4F60位于U+0800到U+FFFF范围内,所以需要使用3个字节。
构造UTF-8编码的二进制表示:
- 第一个字节的最高位是1的个数等于使用的字节数,后面跟一个0,剩余位用码点二进制表示的高位补充。在这种情况下,第一个字节应为:1110xxxx,其中xxxx是码点二进制表示的高4位。将码点二进制的高位4位0100填入第一个字节的后4位:1110 0100。
- 其余的字节的最高位都是10,后续字节用码点二进制表示的低位填充。在这种情况下,第二个字节应为:10xxxxxx,其中xxxxxx是码点二进制表示的中间6位。将码点二进制的中间6位111101填入第二个字节:1011 1101。
- 第三个字节同理:10xxxxxx,将码点二进制的低位6位100000填入第三个字节:1000 0000。
将每个字节的二进制表示转换为十六进制表示:
第一个字节:1110 0100 -> E4(十六进制)
第二个字节:1011 1101 -> BC(十六进制)
第三个字节:1000 0000 -> 80(十六进制)
因此,Unicode码点0x4F60经过UTF-8编码后的二进制为11100100 10111101 10000000,十六进制表示为E4BC80。
将11100100 10111101 10000000丢给计算机,并告诉它这是unicode的utf-8编码,它就会解析出’你’了
即你最后在计算机中,用二进制表示就是11100100 10111101 10000000,十六进制表示就是E4BC80
对于欧元符号€
unicode编码是U+20AC,按照如下方法将其转换成UTF-8编码:
首先,因为U+20AC位于U+0800和U+FFFF之间,所以按照上表可知其UTF-8编码长度是3
0x20AC的二进制是10 0000 1010 1100,将所有位数从左至右按照4、6、6分成三组,第一组长度不满4前面补0:0010,000010,101100
分别给这三组增加前缀1110、10和10,结果是11100010、10000010、10101100,对应的就是\xE2\x82\xAC
\xE2\x82\xAC即为欧元符号€的UTF-8编码
URI
URL
此外,这里还要提一下 URL编码(有时称为百分比编码),它是在 URI 中表示字符的公认方法。这是通过使用三个字符的序列对要解释的字符进行编码来实现的。该三元组序列由百分号字符“%”,后面加上表示原始字符的八位二进制的两个十六进制数字组成。例如,在ASCII中,表示空格的十六进制 0x20 ,其 URL 编码表示形式为 %20。很绕口,总之,只要记得在url中表示一些字符,需要url编码就是了。
GlassFish 任意文件读取漏洞
Overlong Encoding是什么问题?
那么,了解了UTF-8的编码过程,我们就可以很容易理解Overlong Encoding是什么问题了。
Overlong Encoding就是将1个字节的字符,按照UTF-8编码方式强行编码成2位以上UTF-8字符的方法。
仍然举例说明,比如点号.
在 UTF-8 编码中,该值可以用 4 种不同的方式表示:
1 | 2E (00101110) |
所以这似乎允许多种方式来表示每个 unicode 字符。但这在 unicode 标准中是不允许的。
在 UTF-8 标准中,.唯一的编码方式是使用一个字节2E。如果用两个字节C0 AE应该报错,提示过长的表示。
在UTF-8编码中,ASCII字符使用单个字节表示。对于点号,它的Unicode码是U+002E,而在ASCII中,它也是0x2E。因此,在UTF-8中,点号的编码仍然是0x2E。即按照上表,它只能被编码成单字节的UTF-8字符,但我按照下面的方法进行转换:
0x2E的二进制是10 1110,我给其前面补5个0,变成00000101110
将其分成5位、6位两组:00000,101110
分别给这两组增加前缀110,10,结果是11000000,10101110,对应的是\xC0AE
0xC0AE并不是一个合法的UTF-8字符,但我们确实是按照UTF-8编码方式将其转换出来的,这就是UTF-8设计中的一个缺陷。
按照UTF-8的规范来说,我们应该使用字符可以对应的最小字节数来表示这个字符。那么对于点号来说,就应该是0x2e。但UTF-8编码转换的过程中,并没有限制往前补0,导致转换出了非法的UTF-8字符。如果开发不遵守标准,即对输入的 UTF-8 编码的字符或字符串的标准验证较差,就会导致对非法字节序列的解析。
这种攻击方式就叫“Overlong Encoding”。
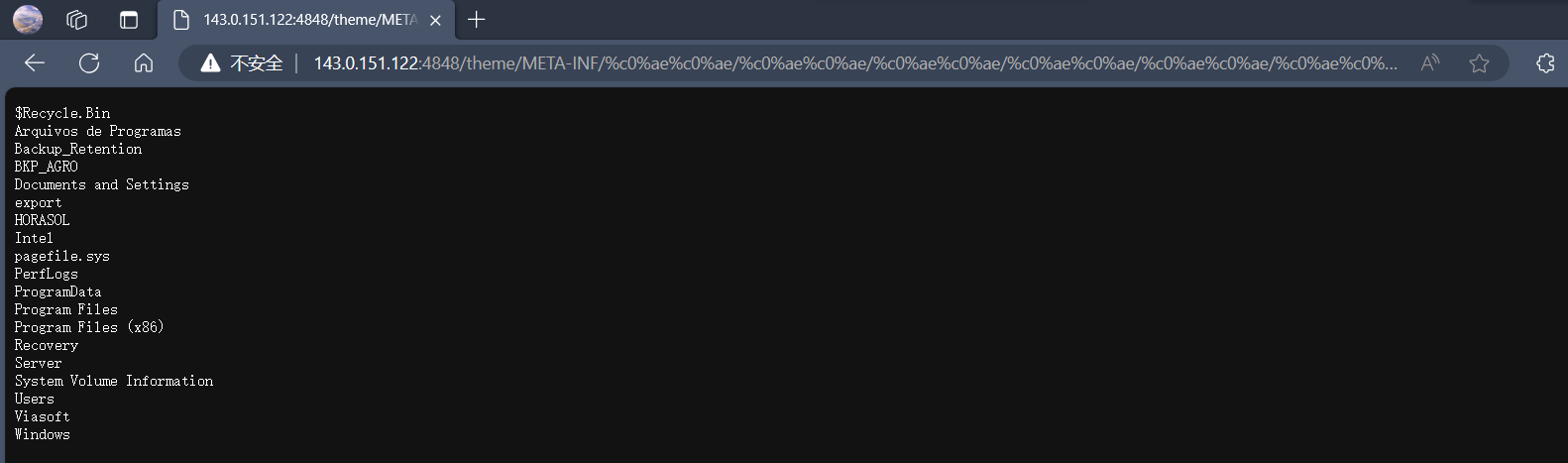
fofa上搜索 "GlassFish" && port="4848",根据搜索出的结果,找到一个 GlassFish 版本为4.1.1的测试
POC
1 | #linux服务器 |
Java反序列化绕WAF
例如有⼀段Base64编码后的序列化数据,那么要我做WAF,我会先将数据进⾏解码获取到byte流,校验是否有序列化的魔术字节,接下来,会进⾏⼀波序列化类的⿊名单 检测。 那么如何检测⿊名单呢,我们知道,对于writeObject后序列化的数据,类名是直接明⽂可读的,例如 有如下的类
1 | package Deserialization; |
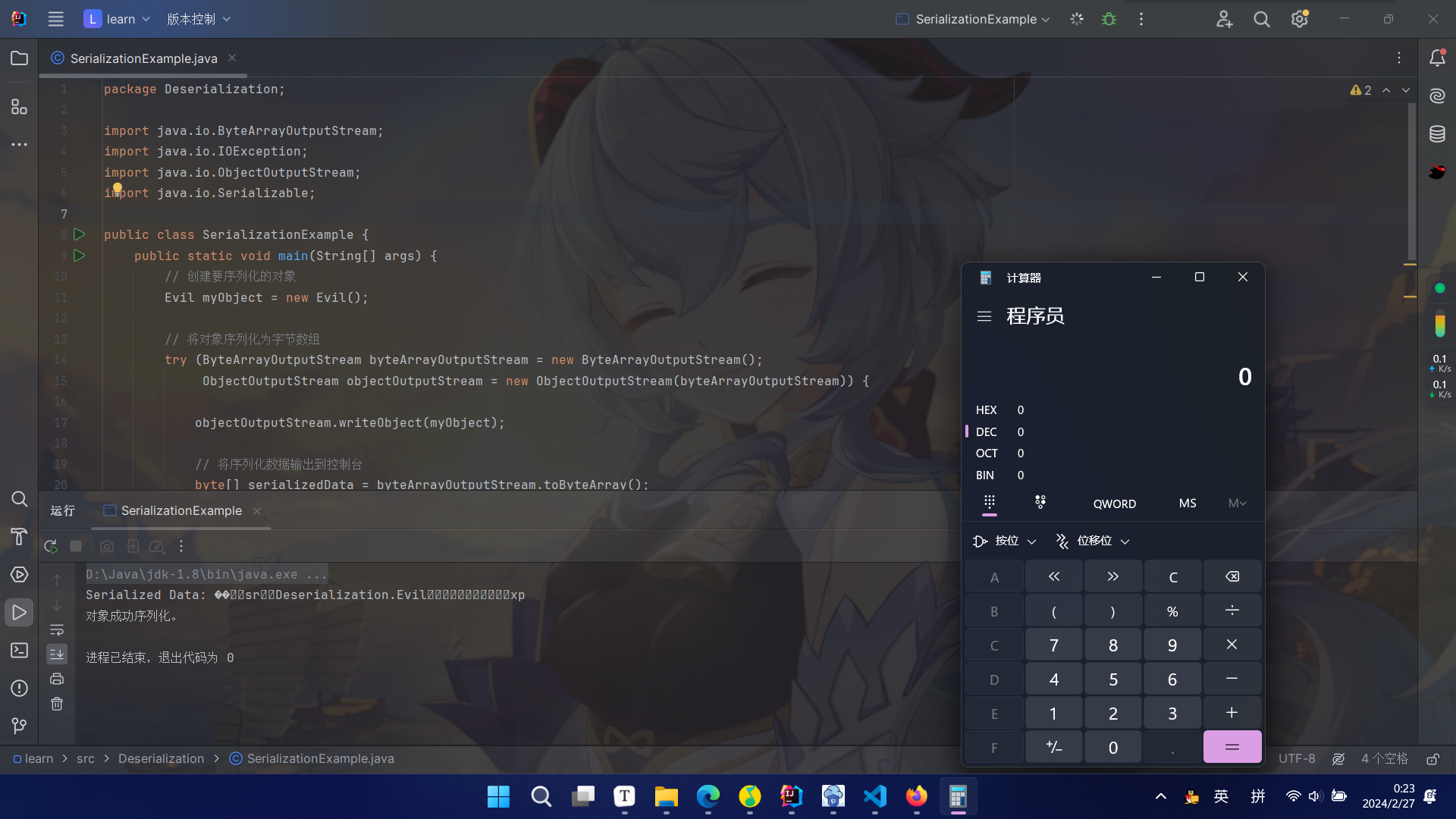
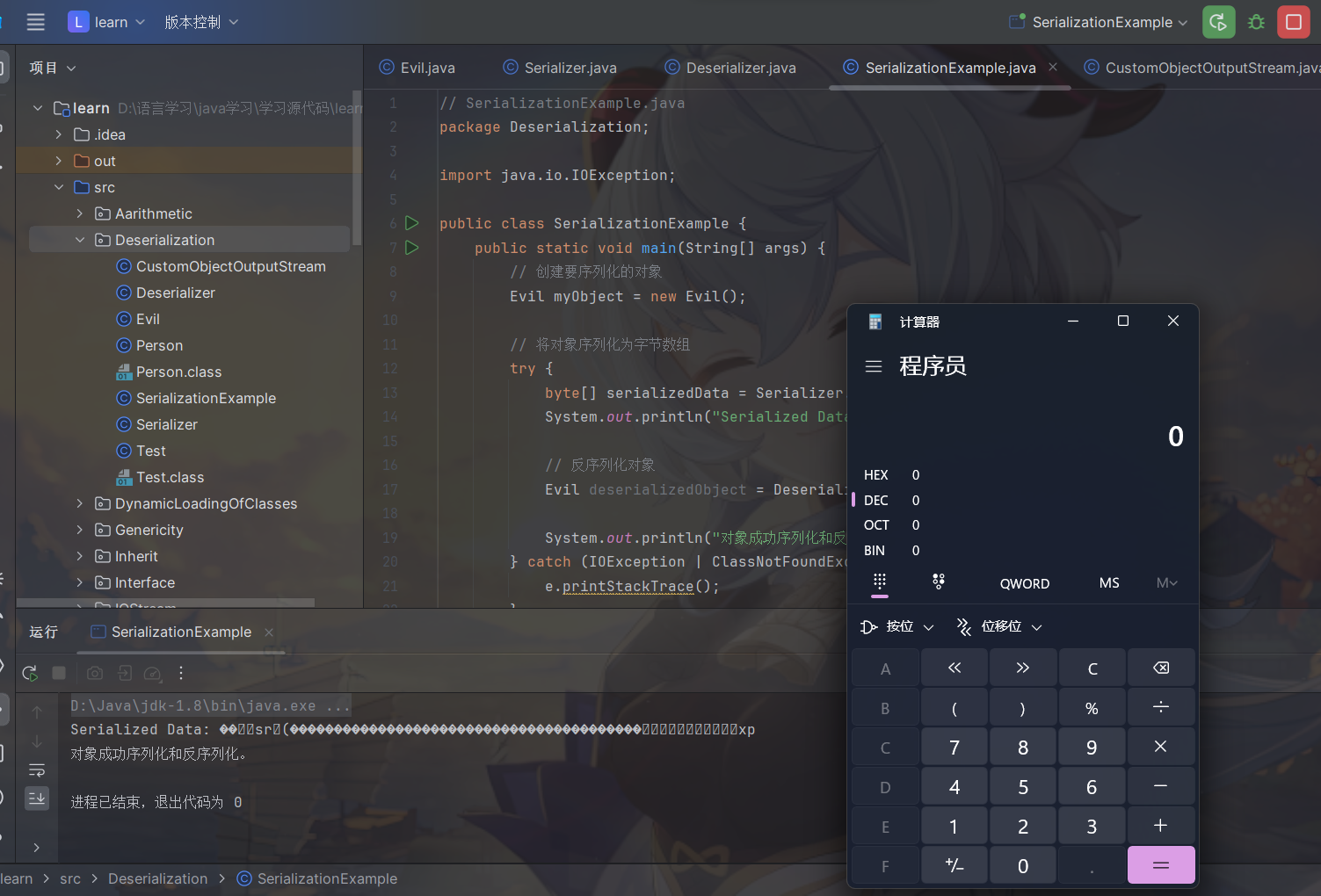
序列化后的数据
1 | ���sr�Deserialization.Evil���������xp |
所以说WAF的思路是检测可⻅字符中是否包含我的black list不就好了,绕过方式就是让序列化后的类名不能被直接看到。
Java在反序列化时使用ObjectInputStream类,这个类实现了DataInput接口,这个接口定义了读取字符串的方法readUTF。在解码中,Java实际实现的是一个魔改过的UTF-8编码,名为“Modified UTF-8”。
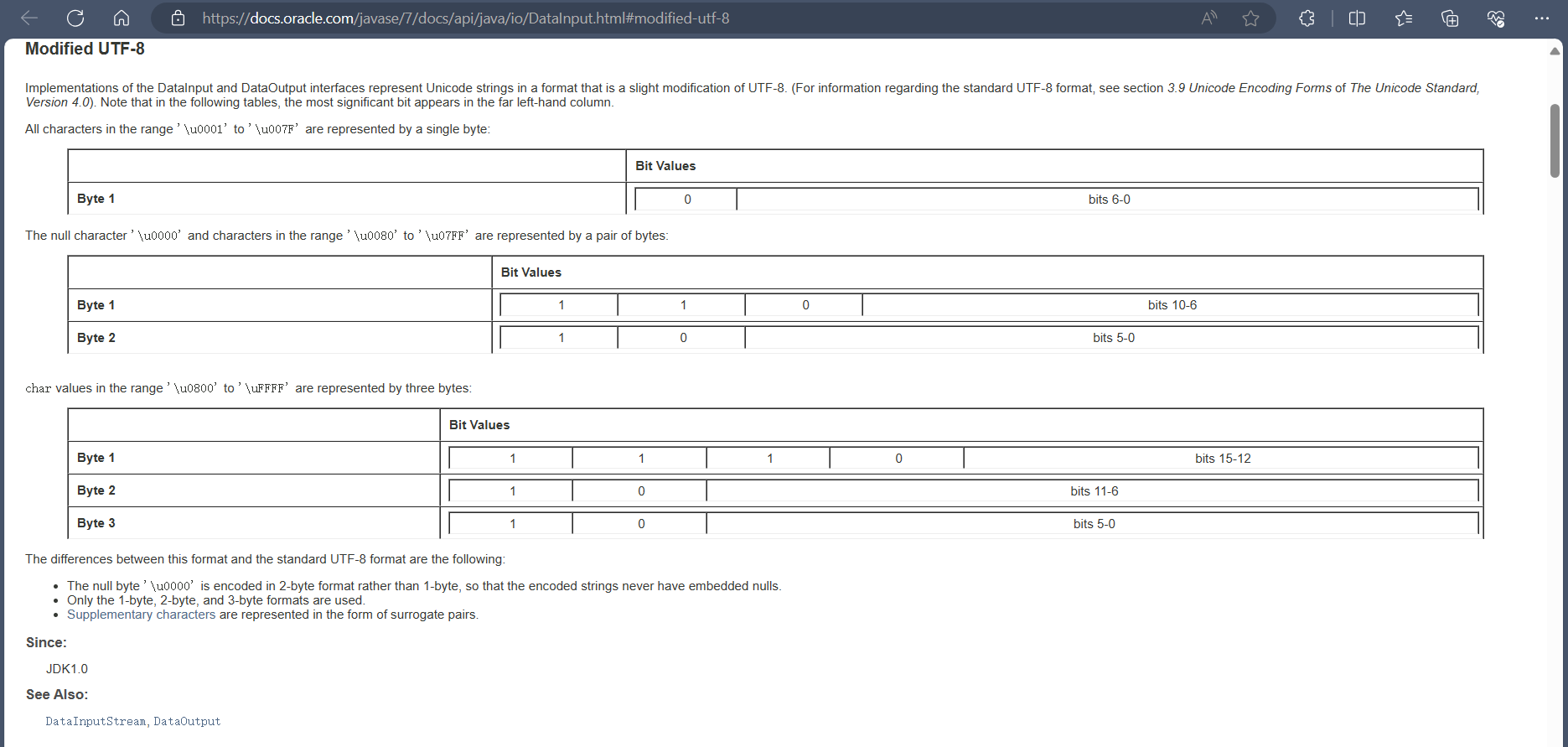
readUTF()方法,按照文档的说明,它在解析2个字节的时候,并不会校验是否满足标准,即对于非法的.的表示11000000 **10**101110 (C0 AE),该方法只检测第一个字节是不是110xxxxx,第二个字节是不是10xxxxxx,都满足就转换为字符。
debug
观测readObject是何时拿取className的
就找Test的那个reedObject,打一个断点,步入。

步入
步入
步入
看一下这个readUTFSpan方法
根据 utflen ,去获取utf的className字符串的值,并添加到sbuf中返回
1 | private long readUTFSpan(StringBuilder sbuf, long utflen) |
调用过程
1 | ObjectStreamClass#readNonProxy(ObjectInputStream in) |
转换脚本
python
直接拿来p神的脚本用来将一个ASCII字符串转换成Overlong Encoding的UTF-8编码:
1 | def convert_int(i: int) -> bytes: |
Java
实现了自定义编码用来混淆类名,将字符映射为整数对,字符映射是通过将字符映射到整数对来实现的。例如,字符 '.' 被映射为整数对 {0xc0, 0xae}。
1 | package Deserialization; |
在序列化时使用这个自定义序列化逻辑即可
看到序列化后的类名不可读
后记
反序列化才刚刚开始学习,以后的链子多多留意这个姿势。还可以添加jvm代理来进行修改。
参考:
https://mp.weixin.qq.com/s/ytz2WsvPSADYHA520Me9-g
https://www.leavesongs.com/PENETRATION/utf-8-overlong-encoding.html