
前言
远程通讯协议的基本原理
网络通信需要做的就是将流从一台计算机传输到另外一台计算机,基于传输协议和网络 IO 来实现,其中传输协议比较出名的有 http 、 tcp 、 udp 等等, http 、 tcp 、 udp 都是在基于 Socket 概念上为某类应用场景而扩展出的传输协议,网络 IO ,主要有 bio 、 nio 、 aio 三种方式,所有的分布式应用通讯都基于这个原理而实现,只是为了应用的易用,各种语言通常都会提供一些更为贴近应用易用的应用层协议。
应用级协议Binary-RPC
Binary-**RPC(Remote Procedure Call Protocol,远程过程调用协议)是一种和RMI(Remote Method Invocation,远程方法调用)**类似的远程调用的协议,它和RMI 的不同之处在于它以标准的二进制格式来定义请求的信息 ( 请求的对象、方法、参数等 ) ,这样的好处是什么呢,就是在跨语言通讯的时候也可以使用。
Binary -RPC 协议的一次远程通信过程:
1 、客户端发起请求,按照 Binary -RPC 协议将请求信息进行填充;
2 、填充完毕后将二进制格式文件转化为流,通过传输协议进行传输;
3 、接收到在接收到流后转换为二进制格式文件,按照 Binary -RPC 协议获取请求的信息并进行处理;
4 、处理完毕后将结果按照 Binary -RPC 协议写入二进制格式文件中并返回。
传输格式:Binary-RPC 使用标准的二进制文件作为传输的标准格式。
请求转化为流:将二进制格式文件转化为流,以便传输。
接收和处理流:接收方监听端口,获取请求的流,转化为二进制文件,根据协议获取请求的信息,进行处理并将结果返回。
传输协议:Binary-RPC 可以基于 HTTP 协议实现,也可以直接在 TCP 协议上实现。
Hessian
Hessian Binary Web Service Protocol (caucho.com)
Hessian二进制web服务协议使web服务可以在不需要大型框架的情况下使用。因为它是二进制协议,所以非常适合发送二进制数据,而不需要用附件扩展协议。
Hessian 可通过Servlet提供远程服务,需要将匹配某个模式的请求映射到Hessian服务。也可Spring框架整合,通过它的 DispatcherServlet可以完成该功能,DispatcherServlet可将匹配模式的请求转发到Hessian服务。Hessian的server端提供一个servlet基类, 用来处理发送的请求,而Hessian的这个远程过程调用,完全使用动态代理来实现的,,建议采用面向接口编程,Hessian服务通过接口暴露。
Hessian处理过程示意图:客户端——>序列化写到输出流——>远程方法(服务器端)——>序列化写到输出流 ——>客户端读取输入流——>输出结果

和JDK自带序列化不同的是,如果一个对象之前出现过,hessian会直接插入一个R index这样的块来表示一个引用位置,从而省去再次序列化和反序列化的时间。
Hessian的序列化速度相较于JDK序列化才更快。只不过Java序列化会把要序列化的对象类的元数据和业务数据全部序列化从字节流,并且会保留完整的继承关系,因此相较于Hessian序列化更加可靠。
不过相较于JDK的序列化,Hessian另一个优势在于,这是一个跨语言的序列化方式,这意味着序列化后的数据可以被其他语言使用,兼容性更好。
并且两者都是基于Field机制,没有调用getter、setter方法,同时反序列化时构造方法也没有被调用。
基本使用
Servlet
这个搞了一天,最后发现是tomcat版本和JDK版本太高了。
添加依赖
1 | <dependency> |
我是使用maven插件来运行tomcat7
1 | <build> |
提供服务的类注册成 Servlet 的方式来作为 Server 端进行交互。
1 | import java.util.HashMap; |
具体实现接口的方法
1 | import java.util.HashMap; |
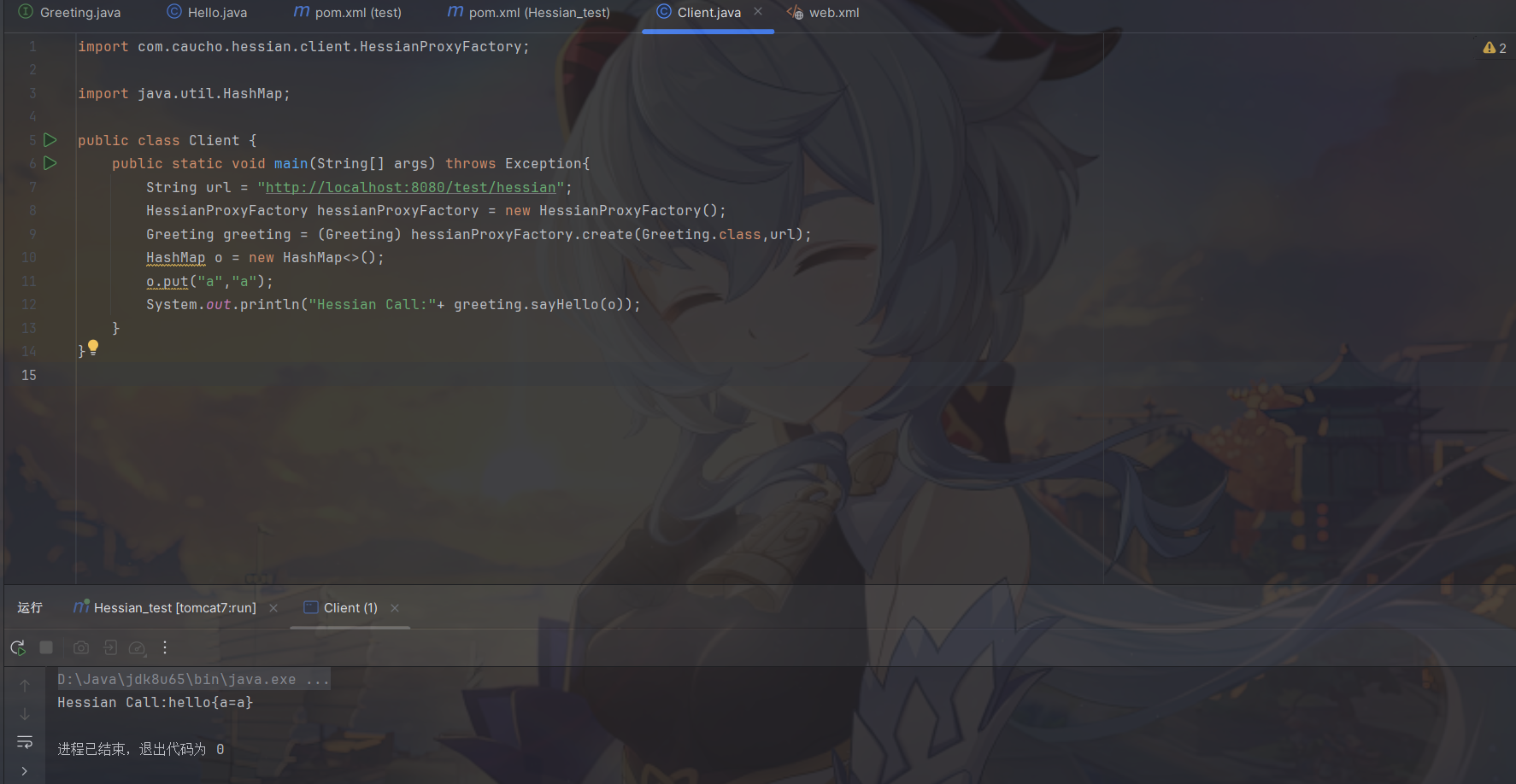
Client
1 | import com.caucho.hessian.client.HessianProxyFactory; |
web.xml有两种写法
具体实现类继承自 HessianServlet
1 |
|
完全通过配置文件进行设置
1 |
|
源码分析
接口的暴露与访问
在 Servlet 中采用继承或配置的时候,都是 com.caucho.hessian.server.HessianServlet 类在起作用,这个类是一个 javax.servlet.http.HttpServlet 的子类。这说明这个类的 init 方法将会承担一些初始化的功能,而 service 方法将会是相关处理的起始位置。
接下来重点关注这两个方法。首先是 init 方法,这个方法总体来讲就是用来初始化 HessianServlet 的成员变量,包括 _homeAPI(调用类的接口 Class)、_homeImpl(具体实现类的对象)、_serializerFactory(序列化工厂类)、_homeSkeleton(封装方法)等等。
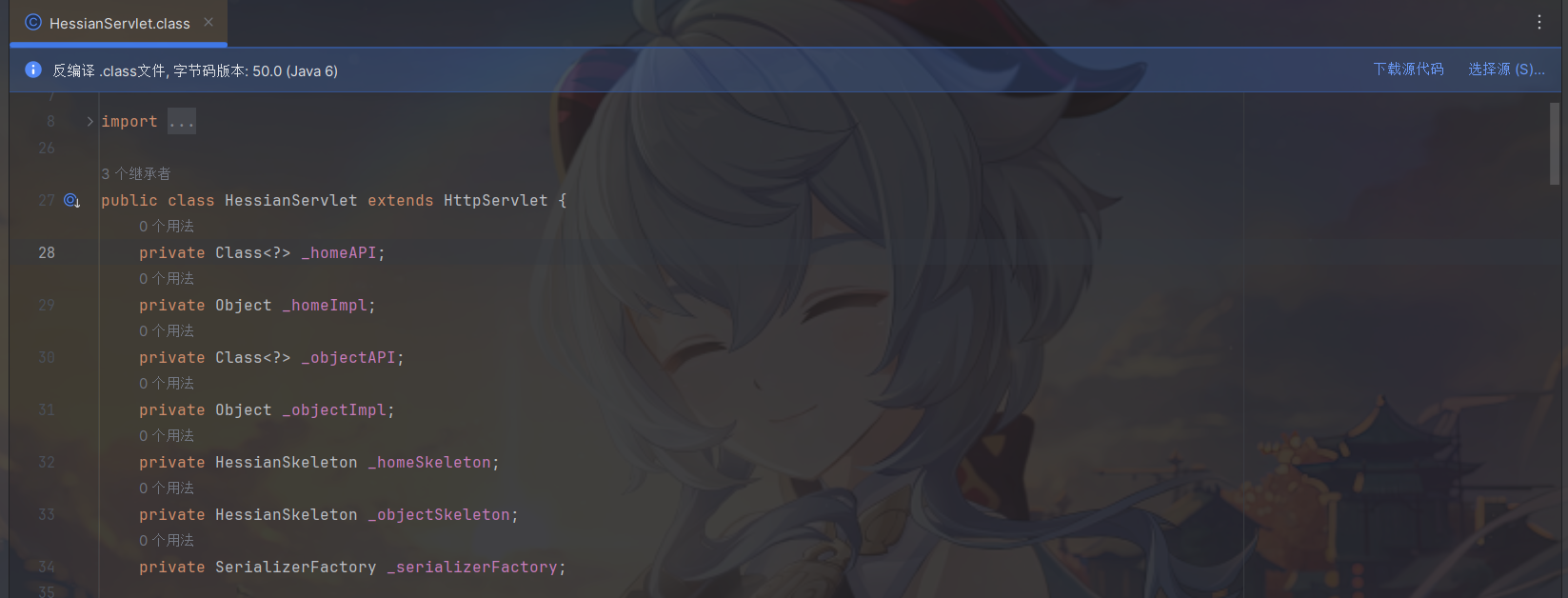
看到com.caucho.hessian.server.HessianServlet#service方法
只接受POST请求。获取参数中的id或者ejbid作为objectId
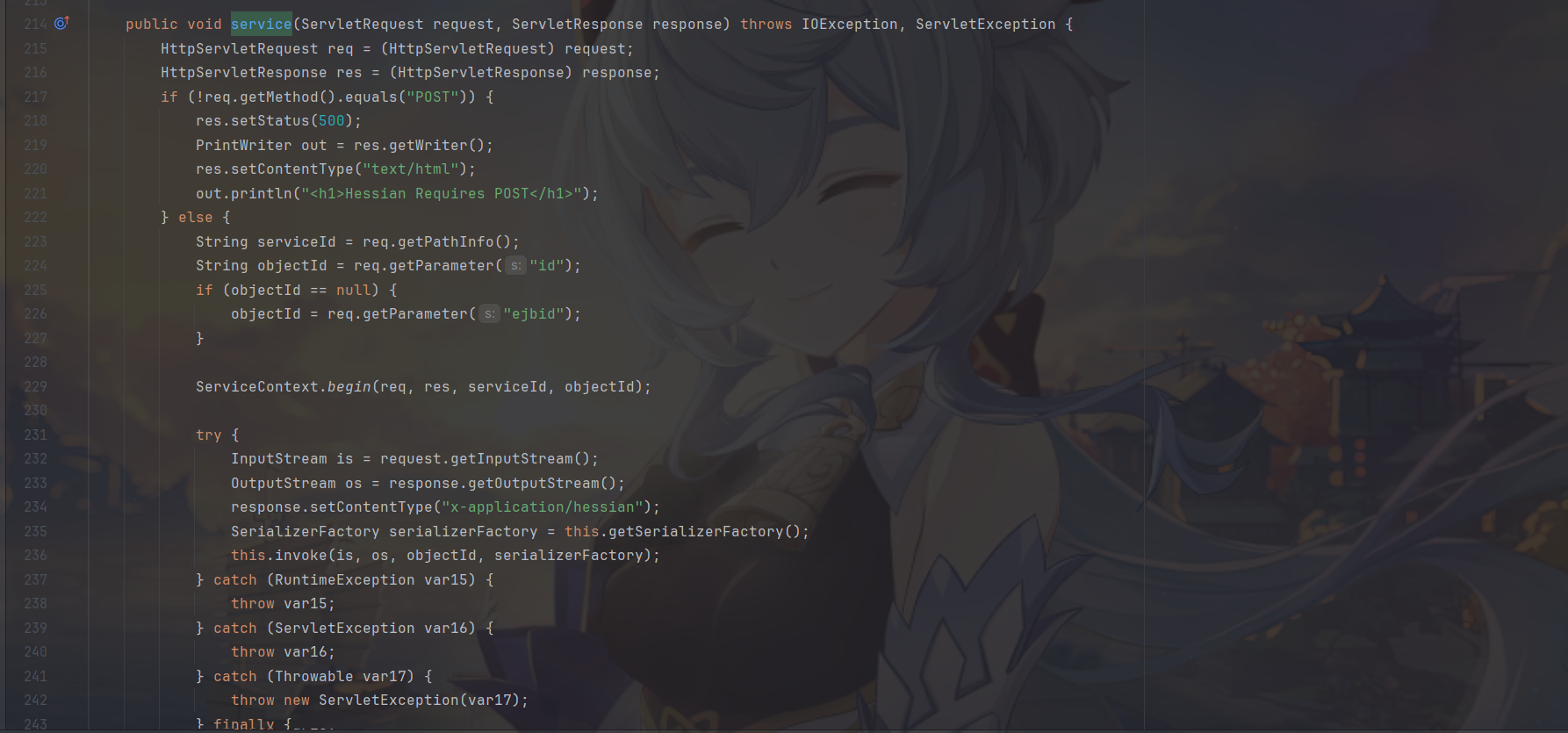
invoke 方法根据 objectID 是否为空决定调用哪个。
通过构造函数获得代理对象并将自定义的InvocationHandler实例对象传为参数传入,对代理实例调用方法时,将对方法调用进行编码并将其指派到它的调用处理程序(InvocationHandler)的invoke()方法。

com.caucho.hessian.server.HessianSkeleton类,HessianSkeleton 是 AbstractSkeleton 的子类,用来对 Hessian 提供的服务进行封装。
HessianSkeleton 初始化时将实现类保存在成员变量 _service 中。
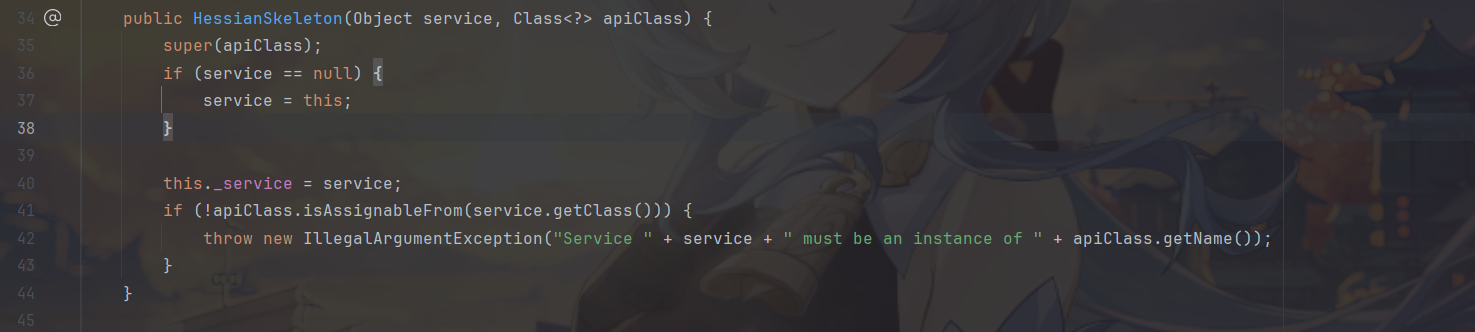
HessianSkeleton 中还有两个成员变量,_hessianFactory 用来创建 HessianInput/HessianOutput 流,_inputFactory 用来读取和创建 HessianInput/Hessian2Input 流

方法com.caucho.hessian.server.HessianSkeleton#invoke(java.io.InputStream, java.io.OutputStream, com.caucho.hessian.io.SerializerFactory)用来输入输出流的创建,然后主要是调用方法的查找和参数的反序列化,反序列化后进行反射调用,并写回结果。
序列化与反序列化流程
Hessian 的序列化反序列化流程有几个关键类,一般包括输入输出流、序列化/反序列化器、相关工厂类等等,依次来看一下。
首先是输入和输出流,Hessian 定义了 AbstractHessianInput/AbstractHessianOutput 两个抽象类,用来提供序列化数据的读取和写入功能。Hessian/Hessian2/Burlap 都有这两个类各自的实现类来实现具体的逻辑。
序列化
对于输出流关键类为 AbstractHessianOutput 的相关子类,这些类都提供了 call 等相关方法执行方法调用,writeXX 方法进行序列化数据的写入,这里以 Hessian2Output 为例。
除了基础数据类型,主要关注的是对 Object 类型数据的写入方法 writeObject:
1 | //com.caucho.hessian.io.HessianOutput#writeObject |
这个方法根据指定的类型获取序列化器 Serializer 的实现类,并调用其 writeObject 方法序列化数据。
在当前版本共有28个实现方法
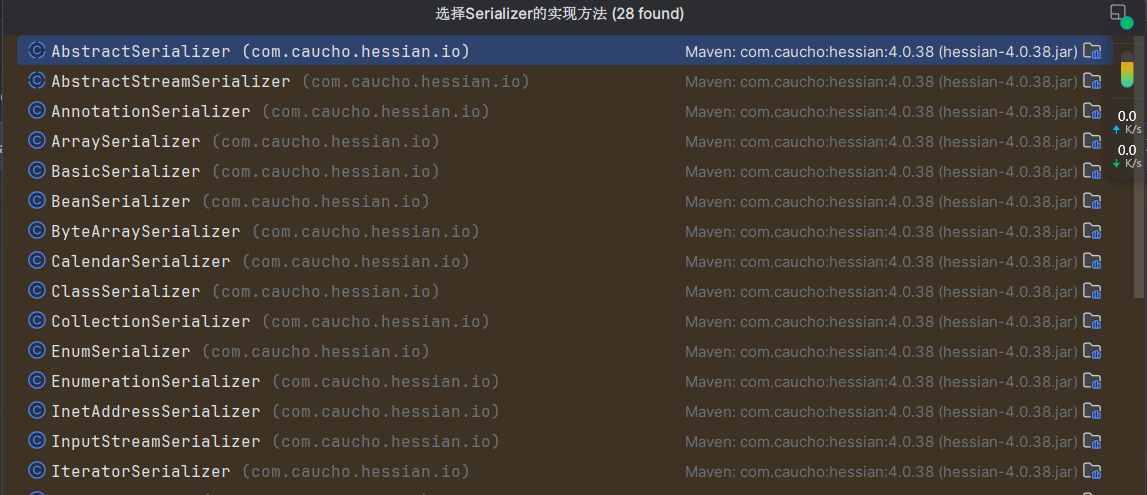
对于自定义类型,将会使用 JavaSerializer/UnsafeSerializer/JavaUnsharedSerializer 进行相关的序列化动作,默认情况下是 UnsafeSerializer。来看看这个类,他的writeObject 方法兼容了 Hessian/Hessian2 两种协议的数据结构,会调用 writeObjectBegin 方法开始写入数据
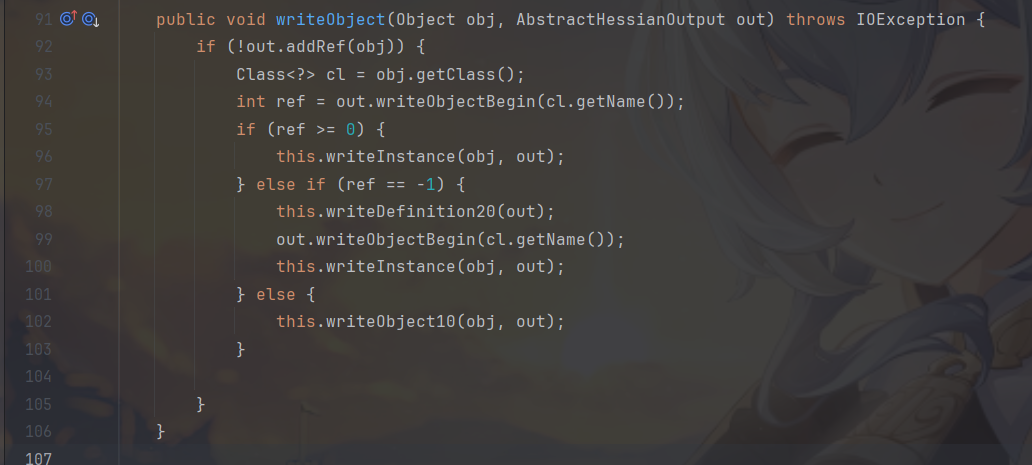
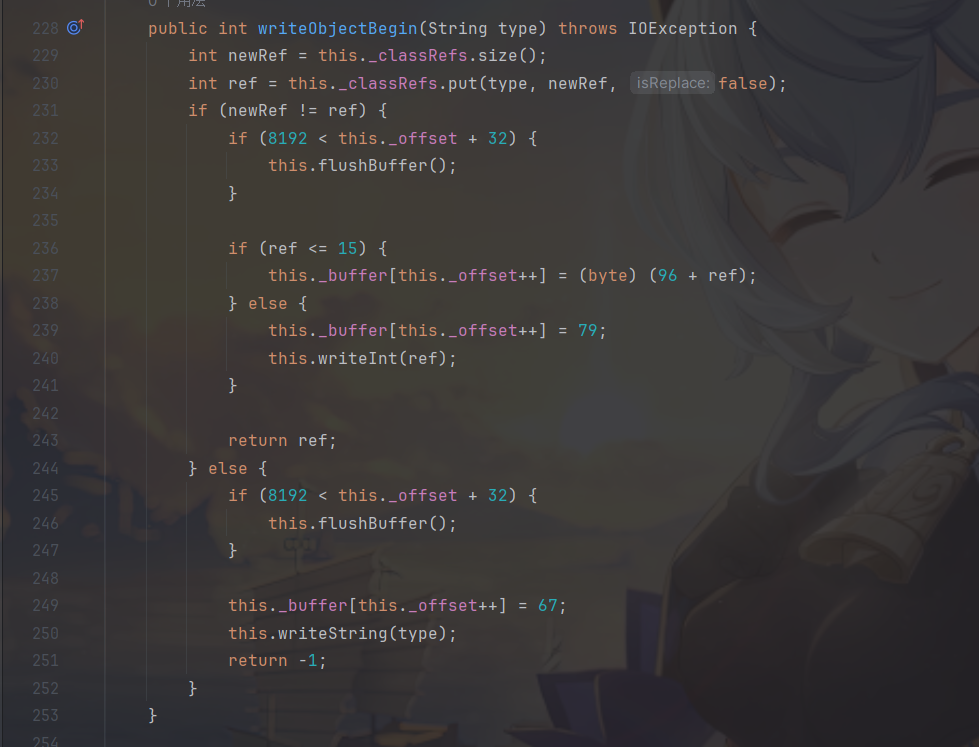
writeObjectBegin 这个方法是 AbstractHessianOutput 的方法,Hessian2Output 重写了这个方法,而其他实现类没有。也就是说在 Hessian 1.0 和 Burlap 中,写入自定义数据类型(Object)时,都会调用 writeMapBegin 方法将其标记为 Map 类型。

在 Hessian 2.0 中,将会调用 writeDefinition20 和 Hessian2Output#writeObjectBegin 方法写入自定义数据,就不再将其标记为 Map 类型。
反序列化
对于输入流关键类为 AbstractHessianInput 的子类,这些类中的 readObject 方法定义了反序列化的关键逻辑。基本都是长达 200 行以上的 switch case 语句。在读取标识位后根据不同的数据类型调用相关的处理逻辑。这里还是以 Hessian2Input 为例。
与序列化过程设计类似,Hessian 定义了 Deserializer 接口,并为不同的类型创建了不同的实现类。
接着来看对自定义类型对象的读取。
在 Hessian 1.0 的 HessianInput 中,没有针对 Object 的读取,而是都将其作为 Map 读取,在序列化的过程中我们也提到,在写入自定义类型时会将其标记为 Map 类型。
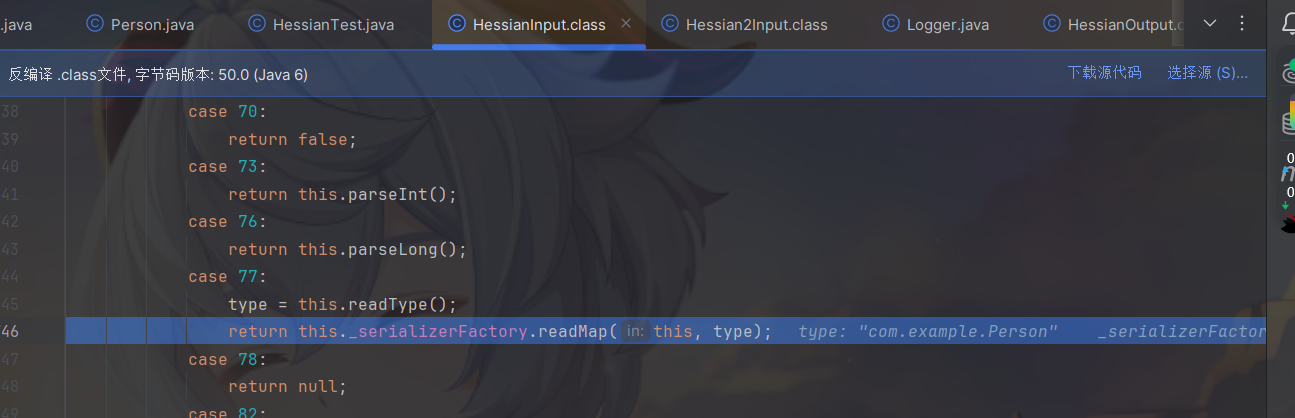
随后会进入到SerializerFactory#readMap中,会进入到getDeserializer方法获取反序列化器,如果获取不到,就会进入到_hashMapDeserializer.readMap中。
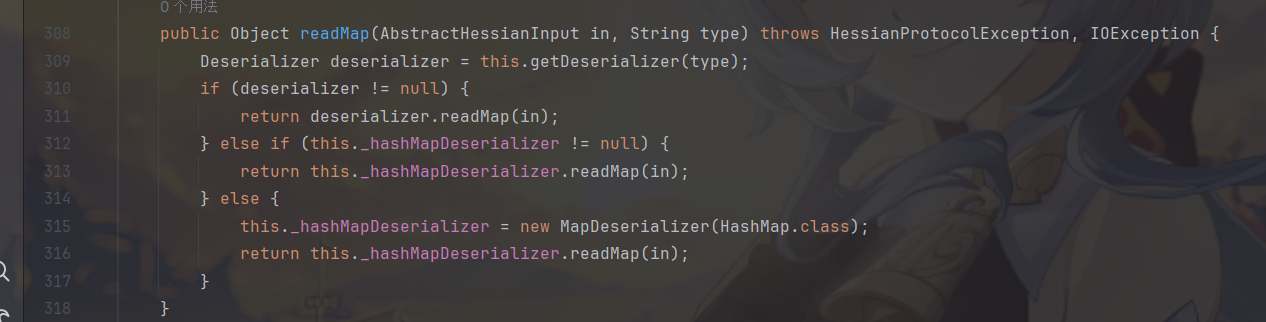
在getDeserializer中,它会判断是否前面获取不到type,是则返回null,然后会从缓存中获取对应type的反序列化器,如果获取不到,会从_staticTypeMap中获取,都获取不到,则判断 type 是不是数组,是就根据数组基本类型来获取其 Deserializer,并创建 ArrayDeserializer 返回,否则尝试通过目标 type 的 clazz 形式来获取deserializer放到缓存里面。一般的类如果使用了不安全的Serializer,会获取到UnsafeDeserilize。
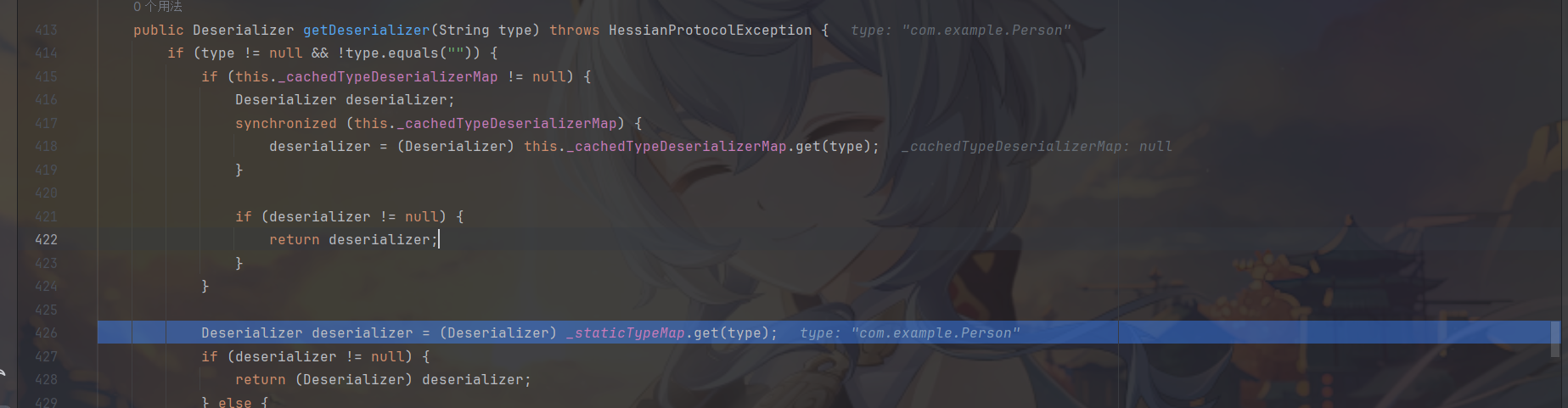
1 | public Deserializer getDeserializer(String type) throws HessianProtocolException { |
MapDeserializer#readMap 方法提供了针对 Map 类型数据的处理逻辑。会对map的类型进行判断,如果是Map则使用HashMap,SortedMap则使用TreeMap(),接着进入了一个 while 循环,它会读取 key-value 的键值对并调用 put 方法,这里的put方法老生常谈了,会触发任意类的hashcode()方法,至此,只要是入口为hashCode都能够使用。
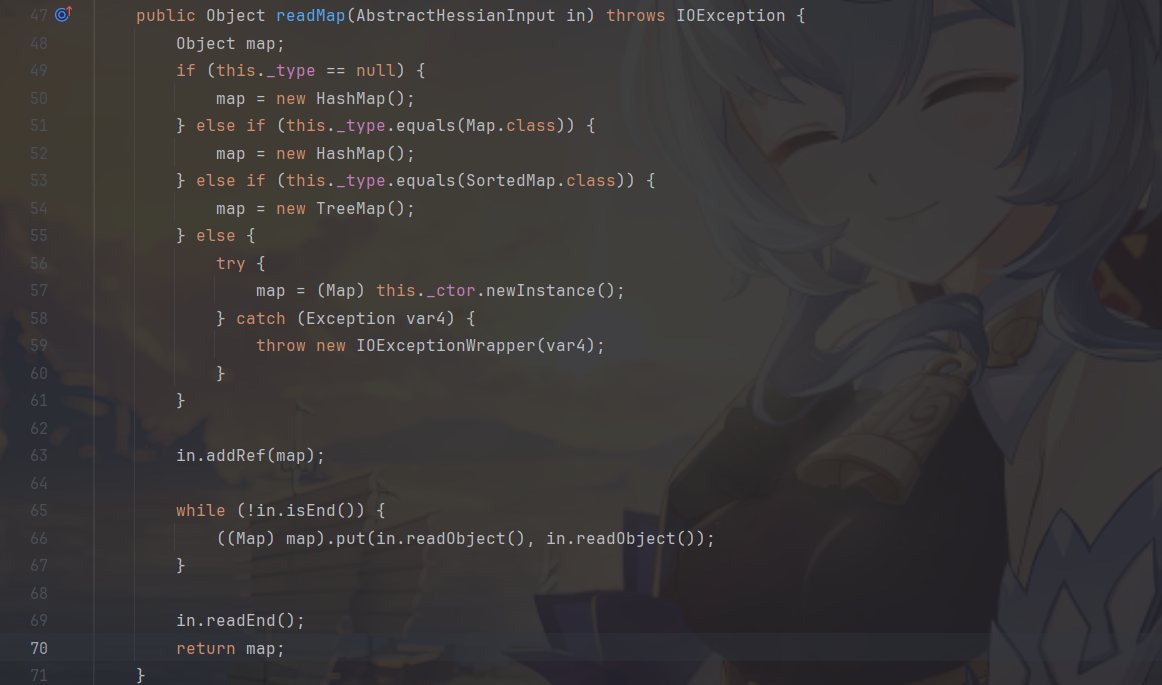
再来看Hessian 2.0,则是提供了 UnsafeDeserializer 来对自定义类型数据进行反序列化,关键方法在 readObject 处。
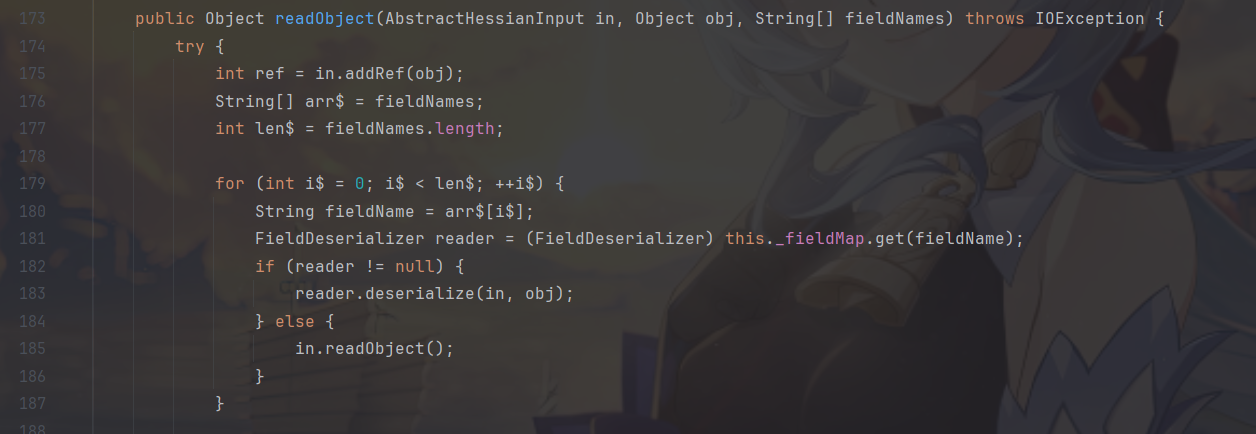
instantiate 使用 unsafe 实例的 allocateInstance 直接创建类实例。
漏洞
可以看到, Hessian 协议使用 unsafe 创建类实例,使用反射写入值,并且没有在重写了某些方法后对其进行调用这样的逻辑。
所以无论是构造方法、getter/setter 方法、readObject 等等方法都不会在 Hessian 反序列化中被触发,那怎么会产生漏洞呢?
答案就在 Hessian 对 Map 类型数据的处理上,在之前的分析中提到,MapDeserializer#readMap 对 Map 类型数据进行反序列化操作是会创建相应的 Map 对象,并将 Key 和 Value 分别反序列化后使用 put 方法写入数据。在没有指定 Map 的具体实现类时,将会默认使用 HashMap ,对于 SortedMap,将会使用 TreeMap。
而众所周知, HashMap 在 put 键值对时,将会对 key 的 hashcode 进行校验查看是否有重复的 key 出现,这就将会调用 key 的 hasCode 方法
也就是说 Hessian 相对比原生反序列化的利用链,有几个限制:
- kick-off chain 起始方法只能为 hashCode/equals/compareTo 方法;
- 利用链中调用的成员变量不能为 transient 修饰;
- 所有的调用不依赖类中 readObject 的逻辑,也不依赖 getter/setter 的逻辑。
这几个限制也导致了很多 Java 原生反序列化利用链在 Hessian 中无法使用,甚至 ysoserial 中一些明明是 hashCode/equals/compareTo 触发的链子都不能直接拿来用。
参考:
Nacos JRaft Hessian 反序列化 RCE 分析 - X1r0z Blog (exp10it.io)
Apache Dubbo 2.7.6 反序列化漏洞复现及分析 - 先知社区 (aliyun.com)
Hessian、Spring、Groovy、Rhino反序列化浅析 - 先知社区 (aliyun.com)